What is artificial intelligence? Why is it important? Why is everyone talking about it all of a sudden? If you skim online headlines, you’ll likely read about how AI is powering Amazon and Google’s virtual assistants, or how it’s taking all the jobs (debatable), but not a good explanation of what it is (or whether the robots are going to take over). We’re here to help with this living document, a plain-English guide to AI that will be updated and refined as the field evolves and important concepts emerge.

What is artificial intelligence? Why is it important? Why is everyone talking about it all of a sudden? If you skim online headlines, you’ll likely read about how AI is powering Amazon $AMZN and Google $GOOGL’s virtual assistants, or how it’s taking all the jobs (debatable), but not a good explanation of what it is (or whether the robots are going to take over). We’re here to help with this living document, a plain-English guide to AI that will be updated and refined as the field evolves and important concepts emerge.
Artificial intelligence is software, or a computer program, with a mechanism to learn. It then uses that knowledge to make a decision in a new situation, as humans do. The researchers building this software try to write code that can read images, text, video, or audio, and learn something from it. Once a machine has learned, that knowledge can be put to use elsewhere. If an algorithm learns to recognize someone’s face, it can then be used to find them in
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
Humans are naturally adept at learning complex ideas: we can see an object like an apple, and then recognize a different apple later on. Machines are very literal—a computer doesn’t have a flexible concept of “similar.” A goal of artificial intelligence is to make machines less literal. It’s easy for a machine to tell if two images of an apple, or two sentences, are exactly the same, but artificial intelligence aims to recognize a picture of that same apple from a different angle or different light; it’s capturing the visual idea of an apple. This is called “generalizing” or forming an idea that’s based on similarities in data, rather than just the images or text the AI has seen. That more general idea can then be applied to things that the AI hasn’t seen before.
“The goal is to reduce a complex human behavior to a form that can be treated computationally,” says Alex Rudnicky, a computer science professor at Carnegie Mellon University. “This in turn allows us to build systems that can undertake complex activities that are useful to people.”
Artificial intelligence researchers are still working on the very basics of this problem. How do we teach computers to recognize what they see in images and video? After that, how does recognition move to understanding—not only producing the word “apple” but knowing an apple is a food related to oranges and pears, and that humans eat apples and can cook with them, and use them to make apple pies, and that it’s connected to the story of Johnny Appleseed, and on and on. There’s also the matter of understanding our language, where words have multiple meanings based on context, definitions are always evolving, and each person has a slightly different way of saying things. How can computers understand this fluid, ever-changing construct?
Progress in AI moves at different speeds depending on the medium. Right now, we’re seeing incredible growth in the ability to understand images and video, a field called computer vision. But that progress does little to help other AI understand text, a field called natural language processing. These fields are developing “narrow intelligence,” which means the AI is powerful at working with images or audio or text, but can’t learn the same way from all three. An agnostic form of learning would be “general intelligence,” which is what we see in humans. Many researchers hope that advancements in individual fields will uncover more shared truths about how we can make machines learn, eventually converging into a unified method for building general artificial intelligence.
Once artificial intelligence has learned how to identify an apple in an image or transcribe a snippet of speech from an audio clip, it can be used in other pieces of software to make decisions that would have once required a human. It can be used to identify and tag your friends in Facebook photos, something you (a human) would have had to do manually. It can identify another car or a street sign in a self-driving car or your car’s backup camera. It can be used to locate bad produce that should be removed in agriculture production.
These tasks, based only off image recognition, would typically be done by either the user or someone in the company providing the software. If a task saves the user time, it’s a feature, and if it saves someone at the company time or eliminates a job completely, it’s a cost saver. There are some applications, like crunching millions of data points in minutes for sales analytics, that could never have been feasible without machines, meaning potential for new information that has never been possible before. These tasks can now be done quickly and cheaply by machines, anytime and anywhere. It’s the replication of tasks once done by humans, and there’s an undeniable economic benefit for endlessly scalable, low-cost labor.
Jason Hong, a professor in Carnegie Mellon University’s Human Computer Interaction Lab, says that while AI can replicate human tasks, it also has the ability to unlock new kinds of labor.
“Automobiles were a direct replacement for horses, but in the medium and long-term led to many other kinds of uses, such as semi-trucks for large scale shipping, moving vans, mini vans, convertibles,” Hong said. “Similarly, AI systems in the short term will be a direct replacement for routine kinds of tasks, but in the medium and long-term we will see uses just as dramatic as automobiles.”
Just as Gottlieb Daimler and Carl Benz didn’t think about how the automobile would redefine the way cities were built, or the effects of pollution or obesity, we are yet to see the long-term impact of this new kind of labor.
A lot of the ideas on how AI should learn are actually more than 60 years old. Researchers in the 1950s like Frank Rosenblatt, Bernard Widrow, and Marcian Hoff were among the first to study how biologists thought neurons in the brain worked and approximate what they were doing with math. The idea was that one major equation might not be able to solve every problem, but what if we used many connected equations, like the human brain does? The initial examples were simple: analyze sets of 1s and 0s coming through a digitized telephone line, and predict what was next. (That research, done at Princeton by Widrow and Hoff, is still used to reduce the echo on telephone connections today.)
For decades many in computer science thought the idea would never work on more complex problems—today it underlies most of the AI pursuits of major tech companies, from Google and Amazon to Facebook and Microsoft $MSFT. Looking back, researchers now realize that computers were not complex enough to model the billions of neurons in our brain, and that massive amounts of data were needed to train these neural networks, as they’re known.
These two factors, computing power and data, have only been realized in the last 10 years.
In the mid-2000s graphics processor unit (GPU) company Nvidia $NVDA concluded that their chips were well-suited for running neural networks, and began making it easier to run AI on its hardware. Researchers found that being able to work with faster and more complex neural networks led to more improvement in accuracy.
Then in 2009, AI researcher Fei-Fei Li published a database called ImageNet, which contained more than 3 million organized images with labels of what was inside. She thought that if these algorithms had more examples of the world to find patterns between, it could help them understand more complex ideas. She started an ImageNet competition in 2010, and by 2012 researcher Geoff Hinton used those millions of images to train a neural network to beat all other applications by more than 10% accuracy, huge margin. As Li had predicted, data was the key. Hinton had also stacked neural networks on top of another—one just found shapes, while another looked at textures, and so on. These are called deep neural networks, or deep learning, and today is mainly what you hear about in the news when someone is referring to “AI.”
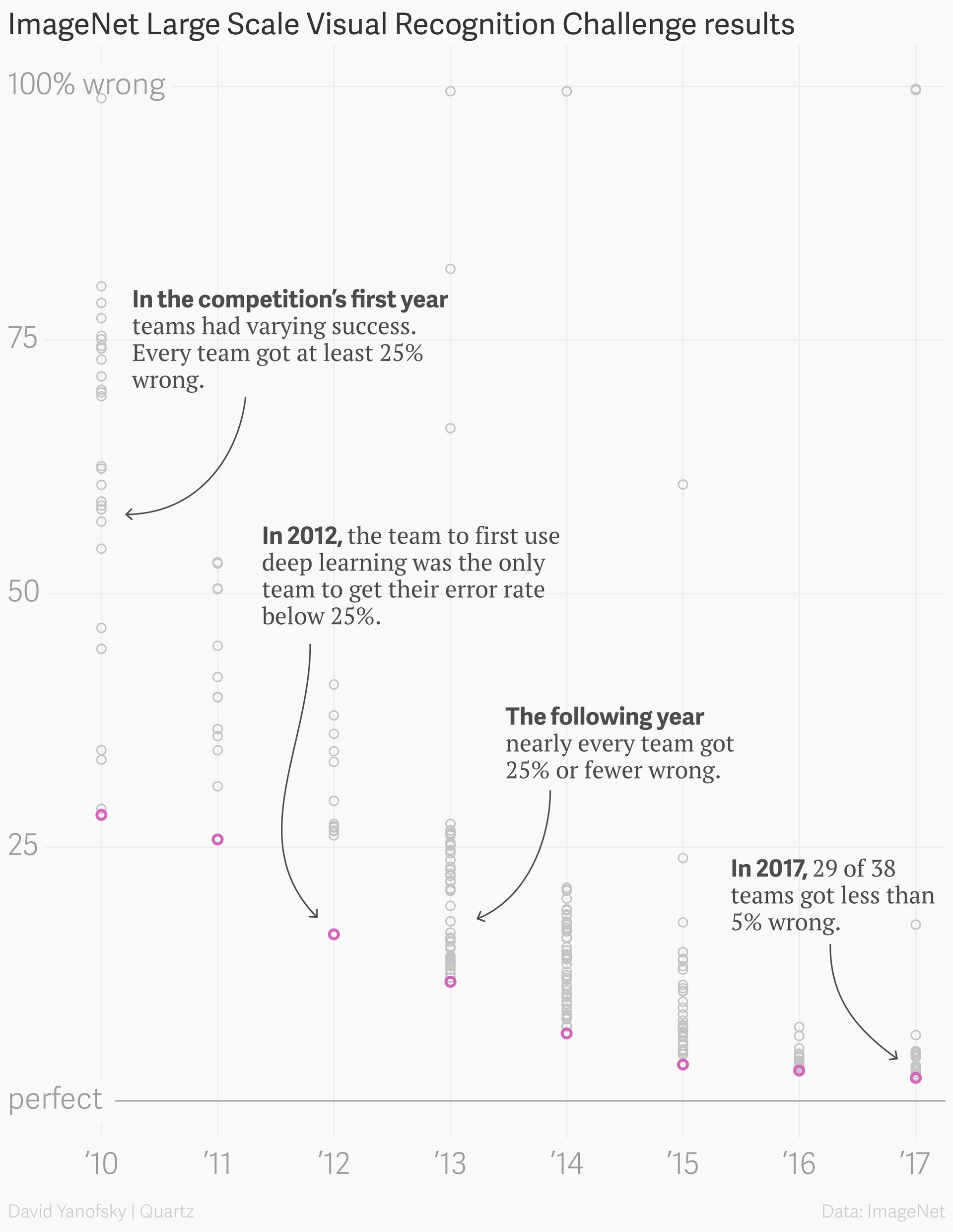
Once the tech industry saw the results, the AI boom kicked off. Researchers who had been working on deep learning in relative obscurity for decades became the new rock stars of tech. By 2015, Google had more than 1,000 projects that used some kind of machine learning.
After watching movies like Terminator, it’s easy to be scared of an all-powerful, evil AI like Skynet. In the AI research world, Skynet would be referred to as general superintelligence, or artificial general intelligence—software that’s more powerful than the human brain in every way. Since computers are able to scale, meaning we can make bigger, faster computers and link them together, the fear is that the power of these robot brains would grow to an unfathomable level. If they’re that smart, they’d be uncontrollable and circumvent any human attempts to shut them off. That’s the doomsday scenario that Elon Musk and Stephen Hawking—immensely smart people—worry about. Despite their intelligence within certain domains, most mainstream AI researchers discount the idea of “summoning the demon,” as Musk has said.
Even if researchers crack the fundamentals of learning, or how to understand the meaning behind patterns and organize that understanding into a functional worldview, there’s no evidence that a computer would have wants or desires or a will to survive, says Yann Lecun, head of Facebook’s AI research lab.
“Behavior like becoming violent when we feel threatened, being jealous, wanting exclusive access to resources, preferring our next of kin to strangers, etc were built into us by evolution for the survival of the species. Intelligent machines will not have these basic behavior unless we explicitly build these behaviors into them,” he wrote on Quora.
There’s no evidence that a computer would find humanity a threat, because there’s no such thing as a threat to a computer. It might be able to define it and be told to operate within parameters that would functionally operate like a will to survive, but that will doesn’t exist.
“The reason I say that I don’t worry about AI turning evil is the same reason I don’t worry about overpopulation on Mars,” Andrew Ng, founding member of Google Brain and former head of AI at Baidu, often says.
But there is one reason to fear AI: humans. It’s been shown that AI are sensitive to picking up human biases in the data it learns from. These biases can be harmless, like recognizing cats in images more often than dogs, because it’s been trained on more cat pictures. But they could also perpetuate stereotypes, like associating the word “doctor” with white males more than any other gender or race. If an AI with that bias were in charge of hiring doctors, it could be unfairly biased against hiring those who aren’t white males. A ProPublica investigation found that algorithms used to sentence those convicted of crimes were racially biased, recommending harsher sentences to people of color. Healthcare data routinely excludes women, especially pregnant women, leading to systems functioning on incomplete data when making medical recommendations to those people. Since these mechanisms make the same decisions that once required humans with the speed of an endlessly powerful machine, we need to make sure they’re making those decisions fairly and consistently with our ethics.
And it’s not easy to tell whether an algorithm is biased. Since deep learning requires millions of connected computations, sorting through all those smaller decisions to figure out their contribution to the larger one is incredibly difficult. So even if we know that an AI made a bad decision, we don’t know why or how, so it’s tough to build mechanisms to catch bias before it’s implemented. The issue is especially precarious in fields like self-driving cars, where each decision on the road can be the difference between life and death. Early research has shown hope that we’ll be able to reverse engineer the complexity of the machines we created, but today it’s nearly impossible to know why any one decision made by Facebook or Google or Microsoft’s AI was made.
Algorithm– a set of instructions for a computer to follow. An algorithm can vary from a simple one-step program to a complex neural network, but is often used to refer to a model (see below).
Artificial intelligence– The catch-all term. Broadly, software meant to mimic or supersede aspects of human intelligence. AI software can learn from data like images or text, experience, evolved, or anything else researchers are yet to invent.
Computer vision– the field of AI research that explores image and video recognition and understanding. This field ranges from learning what an apple looks like to deriving the functional purpose of an apple and ideas associated with it. It’s used as a primary technology for self-driving cars, Google image search, automatic photo-tagging on Facebook.
Deep learning– a field where neural networks are layered to understand complex patterns and relationships within data. When the output of a neural network is fed into the input of another, effectively “stacking” them, the resulting neural network is “deep.”
General intelligence– sometimes referred to as “strong AI,” general intelligence would be able to learn and apply ideas across different tasks.
Generative adversarial network (GAN)– a system in which two neural networks, one that generates an output and another that checks the quality of that output against what it should look like. For instance, when trying to generate a picture of an apple, the generator will make an image, and the other (called a discriminator) will make the generator try again if it can’t recognize an apple in the image.
Machine learning– often conflated with the term “artificial intelligence,” machine learning (ML) is the practice of using algorithms to learn from data.
Model– a model is a machine learning algorithm that builds its own understanding of a topic, or its own “model” of the world.
Natural language processing– software to understand the intent and relationships of ideas within language.
Neural networks– algorithms roughly built to model the way the brain processes information, through webs of connected mathematic equations. Data given to a neural network is broken into smaller pieces and analyzed for underlying patterns thousands to millions of times depending on the complexity of the network. A deep neural network is when the output of one neural network is fed into the input of another, chaining them together as layers. Typically, the layers of a deep neural network would analyze data on higher and higher levels of abstraction, meaning they each throw out data learned to be unnecessary until the simplest and most accurate representation of the data is left.
Reinforcement learning (RL)– an area of machine learning where algorithms learn from experience. An algorithm can control some aspect of its environment, like a video game character, and then learn through repeated trial and error. Since they are highly repeatable, act as models of the 3D world, and are already played on computers, many reinforcement learning breakthroughs have come from algorithms playing video games. RL was one of the main types of machine learning used in DeepMind’s AlphaGo, which beat world champion Lee Sedol in Go. In the real world, it’s been already demonstrated in areas like cybersecurity, where software learns to trick anti-virus software into thinking malicious files are actually safe.
Superintelligence– artificial intelligence more powerful than the human brain. Difficult to define because we still cannot objectively measure much of what our human brains can do.
Supervised learning– a type of machine learning where, when being trained, the algorithm is given data that’s already organized and labelled. If you’re building a supervised learning algorithm to identify cats, you would train the algorithm on 1,000 images of cats labelled “cat.”
Training– the process of teaching an algorithm by supplying it data to learn from.
Unsupervised learning– a type of machine learning where the algorithm is not given any information about how it should classify or categorize the data, and must find those relationships for itself. AI researchers like Facebook’s LeCun see unsupervised learning as the “holy grail” of AI research, as it’s very similar to the way humans naturally learn. “The brain is much better than our model at doing unsupervised learning,” LeCun told IEEE Spectrum. “That means that our artificial learning systems are missing some very basic principles of biological learning.”