By now you’ve probably heard about the audio version of the Great Dress Debacle that’s turning citizens of the internet against each other in a battle of perception. If you haven’t, here’s the tl;dr: There’s an audio clip of a male computer-generated voice saying a word. To some people, the word sounds like “yanny.” To others, it sounds like “laurel.”

By now you’ve probably heard about the audio version of the Great Dress Debacle that’s turning citizens of the internet against each other in a battle of perception. If you haven’t, here’s the tl;dr: There’s an audio clip of a male computer-generated voice saying a word. To some people, the word sounds like “yanny.” To others, it sounds like “laurel.”
To try to find out what is going on here, I emailed neurobiologist Nina Kraus, who runs Brainvolts, the auditory neuroscience laboratory at Northwestern University in Evanston, Illinois. She cc’d some of her labmates on the email and wrote:
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
We only hear “Yanny” and can’t convince ourselves that it’s remotely close to “Laurel.”
This is a clear victory for Team Yanny but still doesn’t answer the question of what the hell is going on here.
For that, Kraus connected me to Brad Story, a professor of speech, language, and hearing sciences at the University of Arizona. He ran the YannyLaurel clip through a waveform detector that visualizes the frequencies present in audio clips. Spoiler alert: It’s probably laurel.
Here’s what came out of the waveform detector:
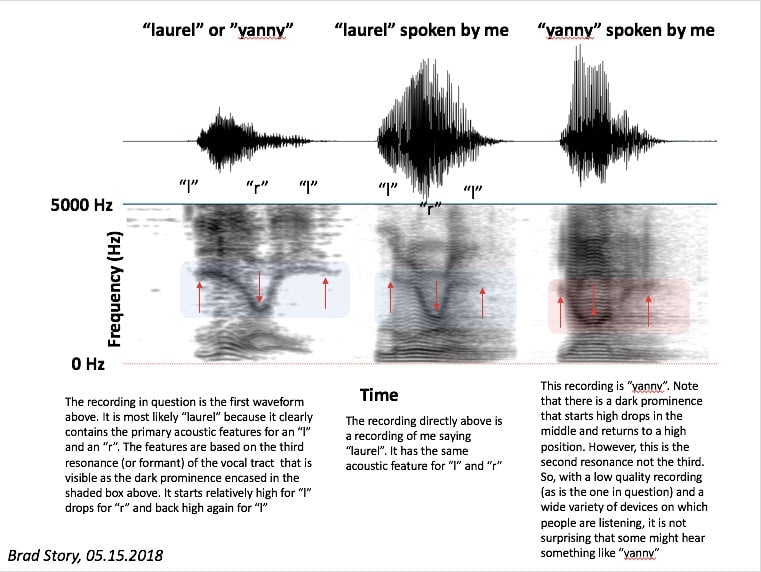
The audio-frequency patterns of both words, when spoken by the researcher, are fairly similar. Speakers, like those in your computer or cellphone, reproduce sound by vibrating at certain frequencies. If two sounds—or in this case words—have similar resonant frequencies, they might end up sounding the same. “So, with a low quality recording (as is the one in question) and a wide variety of devices on which people are listening, it is not surprising that some might hear something like ‘yanny,’” Story wrote. But Story says the “laurel” waveform is a better match, so this robot voice is probably saying “laurel,” not “yanny.” Congrats to Team Laurel. Honestly why the heck would it be saying yanny anyway.
Another principal of audio cognition might apply in this case: “The way you hear sound is influenced by your life in sound—what you know about sound,” Kraus says. Once you are trained to hear a sound, you’re more easily able to hear that sound. And sound trains the brain very quickly.
As an example, Kraus emailed me two audio clips: The first was a snippet of speech so distorted as to be unintelligible. The second clip was of the same speech, but less distorted, so I could actually understand what the speaker was saying.
Once I knew what the speaker was saying, I was quickly able to divine the same words in the first, distorted clip. The incoherent noises I heard before were gone for good. That might explain why some people are stuck hearing only “yanny,” or only “laurel.” Once your brain has processed a sound as having a certain meaning, it is hard to hear it another way.
Kraus and her colleagues have also found that musicians and bilingual people are better able to process sounds. Perhaps that means those who are better trained at listening for meaning could be more adept at hearing both “yanny” and “laurel”—but there’s yet to be a scientific study to investigate that question. Someone for the love of God get a grant for this.
Update: This story has been updated to include additional analysis from audio science researchers.