For many businesses, big data is superfluous. Except, a recently-published paper on the mathematics of big data reveals, when it isn’t. It turns out there is a kind of data that, like black holes or evil wizards of Middle Earth, only becomes more powerful the larger it grows. What’s more, suggest researchers Enric Junqué de Fortuny, David Martens and Foster Provost, even if you’re not gathering this kind of data at present, the new results suggest you may lose out to a competitor who is.

For many businesses, big data is superfluous. Except, a recently-published paper on the mathematics of big data reveals, when it isn’t. It turns out there is a kind of data that, like black holes or evil wizards of Middle Earth, only becomes more powerful the larger it grows. What’s more, suggest researchers Enric Junqué de Fortuny, David Martens and Foster Provost, even if you’re not gathering this kind of data at present, the new results suggest you may lose out to a competitor who is.
To understand what’s going on—stay with us, it’s worth it—you have to know whether your data is dense or sparse. Most businesses are gathering data about their customers and clients such that a great deal is known about any one person. For example, you survey a handful of customers in depth, as in a customer survey comprised of dozens of questions. This is “dense” data, with lots of information on every person, object or event you’re cataloging.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
But the most useful data, in part because it’s still hard to get your hands on or evaluate properly, is called “sparse” data. This is the kind of data the web’s giants, like Google $GOOGL and Facebook $META, gather all the time. It’s “sparse” because all you’re getting is a few data points from any one person, when you could be getting thousands or even millions. Take Netflix $NFLX’s movie rating database, for example—if a person could rate all of the movies in Netflix’s database, Netflix would have perfect knowledge about that person’s tastes. But we can only watch and evaluate so many movies, so for most of the films in the database, Netflix knows zip about our tastes. Hence, sparse data.

A different recent study of companies concentrated not on the mathematics of how companies use sparse data, but the economic benefit that accrues to the companies that do. After controlling for other factors that could account for increased performance, the researchers behind that study found companies using more big data were more productive than their peers, and those using less big data were less productive.
In paper-speak, here’s how that’s quantified:
“…using big data technologies is associated with significant additional productivity grown. Specifically, one standard deviation higher utilization of big data technologies is associated with 1%-3% higher productivity than the average firm; one standard deviation lower in terms of big data utilization is associated with 1%-3% lower productivity. This leads to potentially very large productivity differences between the firms at the extremes.”

So now we have two papers about the impact of big data that is sparse. One shows that using more sparse data leads to an economic advantage. The other, which we’ll concentrate on for the rest of this piece, dives into the mathematics of big data, showing that with sparse data, there’s no such thing as enough.
To understand why firms gathering certain kinds of data seem to be benefiting from it, you have to understand the nature of the kind of data that they’re gathering. A classic example is the data gathered by energy companies. Sure, the world is filling up with smart thermostats and the like, but each model is reporting back to the utility company different kinds of data, at different rates, and it might even be measured in different ways. Now imagine you put all that data into a single spreadsheet—all day long you’ll be creating columns that can only be filled by data gathered by some smart thermostats and not others. For all the customers with a particular thermostat, the columns you created for the data generated only by other types of thermostats will be filled with “0” values. Most of your spreadsheet, in fact, will be filled with zeroes. This is sparse data.
Now think about the entire world, and all the sensors in it. You’ve got security systems, temperature and humidity sensors, location data pouring in from cell phones, and an every wider array of gadgets connected to the Internet of Things. All of them are going to report back in their own way, and any given business might only have access to some subset of this data. It’s a mess. And yet there’s a tremendous amount of value even in this sparse data.
Here’s a chart showing this effect. All you really need to notice is that in every case, the more people who are represented in a database (x-axis) the more accurately a computer can make predictions about any subsequent individuals (y-axis).
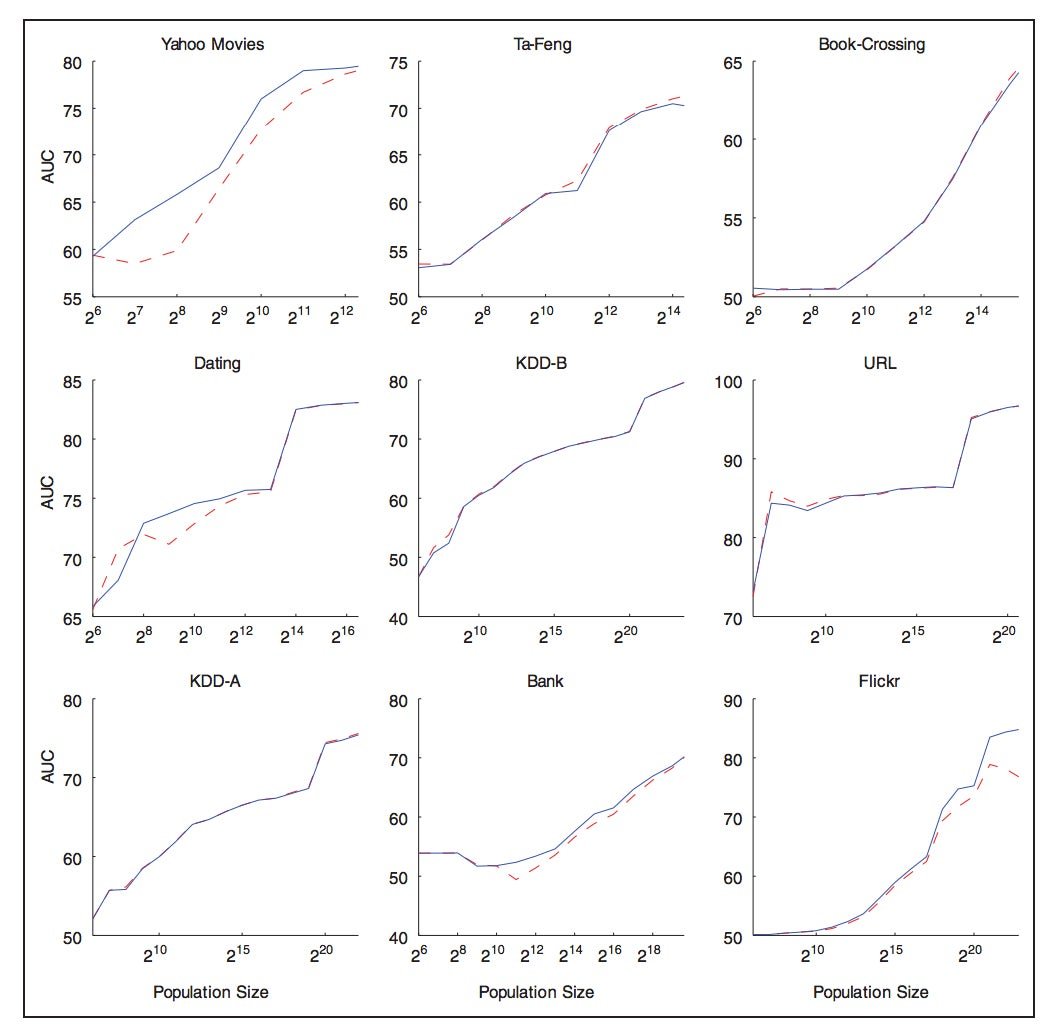

Here’s how the authors sum up their own work:
“These results are not only of interest to pundits preaching about the value of big data, but also have important implications for businesses and other institutions faced with competition. We have have shown that predictive modeling […] can be made substantially more accurate by increasing the data size to a massive scale. This provides one of the clearest illustrations […] that large data sets are indeed potentially even more valuable when it comes to [prediction].”
And, in case that isn’t clear enough:
“This implies that institutions with larger data assets—plus the ability to take advantage of them—potentially can obtain substantial competitive advantage over institutions without access to so much data, or without the ability to handle it.”
Let’s take the example of an energy company once more. An energy company that doesn’t have the chops to handle massive amounts of sparse data is, by its nature, not able to ingest and process the wide variety of potential data sources—from smart meters to weather—that could help that company predict demand, which is important to getting the best prices for energy (and keeping the grid intact). This research suggests that sparse data is the one kind for which there is no such thing as too much. The more you have, the more accurate your predictions can be. Indeed, in the case of predicting events that happen rarely, like freak accidents, you may not be able to predict them at all unless you have really massive data.
It would be easy to brush this off as a problem that is native only to “technology” companies—web companies, energy companies, companies bristling with internet-connected doodads. But here’s the problem: Increasingly, there is no longer such a thing as a “technology” company. Everyone who makes things has inventory to track and supply chains to manage. The financial services industry, for example, is almost nothing but data. Every retailer has purchasing data pouring in. Even companies that are strictly in the service business are finding new ways to use big data to streamline the way they work. And this trend is only accelerating—retailers, in particular, are going to start adding things like centimeter-precision location data to the torrent of information they must process.
What this means is that companies that aren’t at the top of their industry in gathering and acting on the kind of big data where more is only better—i.e., sparse data—could, according to at least two distinct strains of research, lose out to competitors who are.
If your company already has a data scientist on staff, here’s the takeaway for those who are in the know: When you’re gathering sparse data, it’s not just having more data (more samples) that counts; the more kinds of information you’re gathering about each individual (more features) also leads to better results. And even though much of data science these days is about filtering out the features that seem to contribute less to your predictions, this latest research suggests that data scientists may want to rethink that standard way of practicing their craft.