I did a 23andMe genetic test because I suspected I might be partially descended from Middle-Eastern medieval merchants, who were Korea’s first Occidental trading partners. (My feeble basis for this theory included my hair texture and a possible epigenetic explanation for my Jewish conversion.)

I did a 23andMe genetic test because I suspected I might be partially descended from Middle-Eastern medieval merchants, who were Korea’s first Occidental $OXY trading partners. (My feeble basis for this theory included my hair texture and a possible epigenetic explanation for my Jewish conversion.)
But the data took me in some strange directions. As did the horrifying lack of data.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
I doubt that most 23andMe users realize how paltry the company’s data is for non-Caucasians. For example: The data set that 23andMe used to generate my report has 76 Koreans in it, according to Dr. Joanna Mountain, the company’s senior director of research. Seventy-six Koreans. It is estimated there are at least 7 million Koreans living outside of the Korean peninsula—including 1.7 million in the US—among a worldwide population of 83 million.
Seventy-six Koreans seemed small to me, but what do I know? I’m just a journalist. So I spoke to geneticist Spencer Wells, founder and former director of National Geographic’s Genographic Project (arguably a 23andMe competitor), which he ran from 2005-2015. “[76] is a really low number,” he concurred.
Asian-Americans have the highest household incomes of any ethnic group, and they like to buy stuff. If you can’t get more than 76 Koreans to buy your product, you are probably not very good at running a business.
Let us rewind to a more innocent time when I thought this report was going to be accurate. The envelope, please: Based on the 23andMe report, I have zero Middle-Eastern genetic markers.
Also, astonishingly, the report shows that I am 13.4% Japanese and 14% Chinese—and only 61.6% Korean. I was looking forward to watching my parents freak out. My sister texted me, “Oh [Dad will] probably blame Mom.”
To my disappointment, my parents did not freak out, nor did they get into an amusing argument about which of their ancestors was the ho. Because they simply did not believe the data. And, for once, they were right.
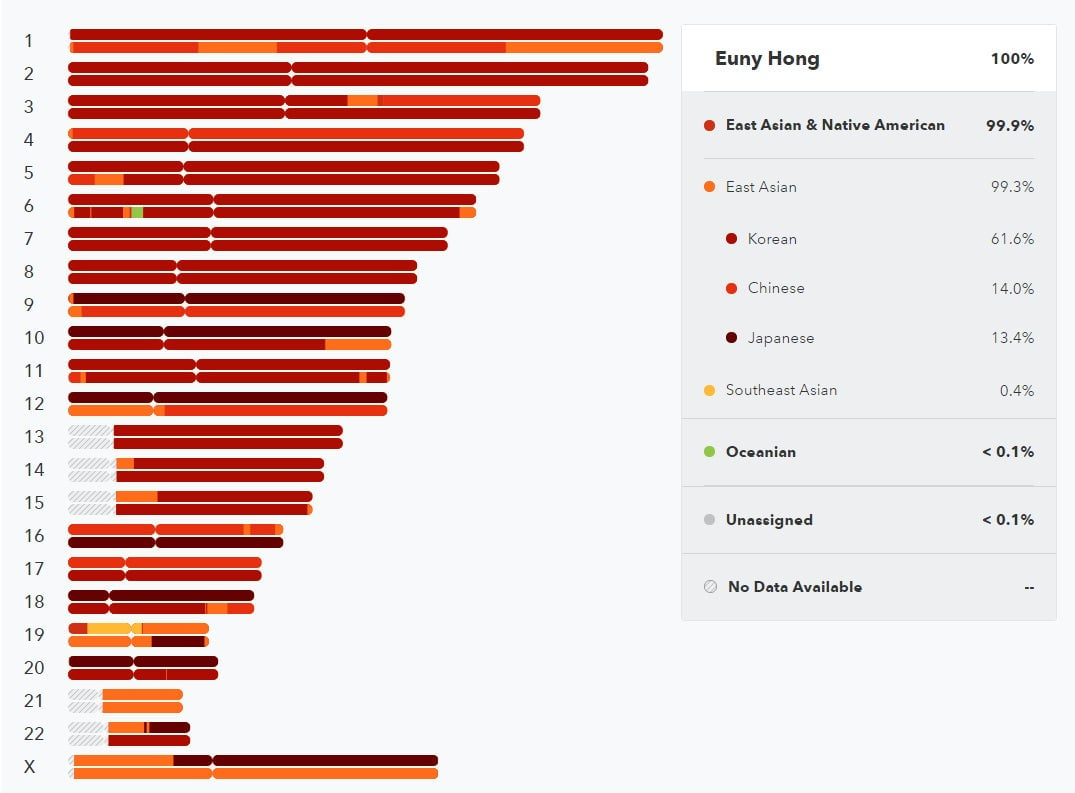
I asked Wells whether my percentage breakdowns of Korean, Chinese, and Japanese meant anything. “Yes,” he said, “but I think it is misleading to go to a decimal place or even to go out two digits.” Wells said that another problem with the data is that “Most of those [samples] are from the US. They’re not terribly useful for studies of indigenous composition—which is effectively what this analysis is trying to do.”
I also interviewed Harvard geneticist Robert Green, who made the important point that private companies have different methods and standards from those of an academic lab. “There is a difference between analysis you can do with hundreds of [genetic] markers at a research level, and the kind of analysis that even the best companies can do, which is more an approximation,” he said.
A few of the geneticists I interviewed for this article (but not Green or Wells) outright accused 23andMe of commercially driven ethnic bias. For example, no distinction is made between northern and southern Chinese, who have very different traits. This was a serious allegation, so I put the question directly before 23andMe’s Mountain. “As a scientist, I find that insulting,” she said in a phone interview.
To further expound on the Asian genetic data, she pointed me to one part of the report, “Reference Set Populations,” which gives the precise sizes of the tested populations. Unfortunately, the data made the opposite point that Mountain was seemingly trying to make. (It is worth mentioning that both Wells and Green expressed great respect for Mountain as a scientist.)
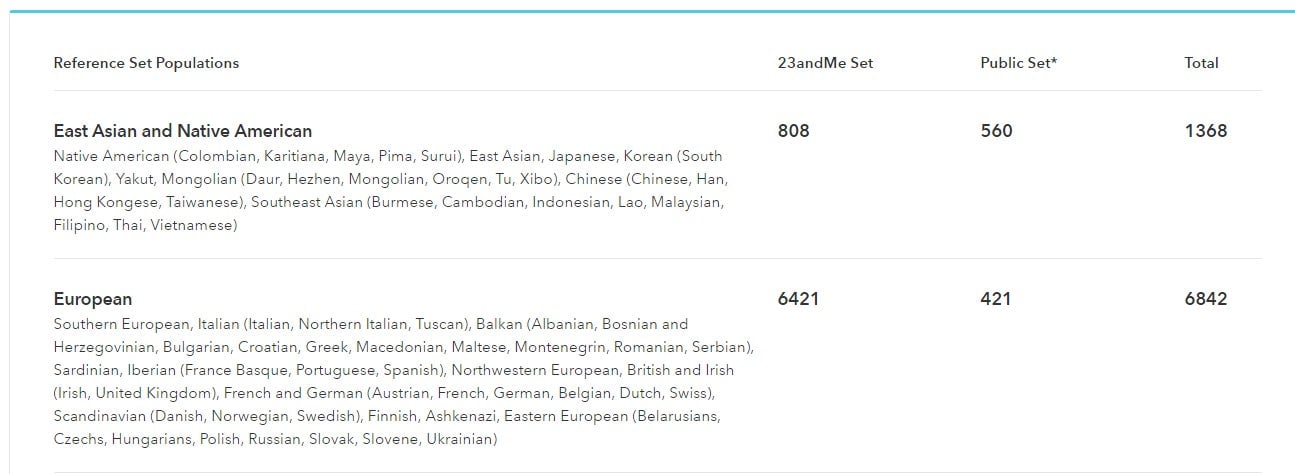
These numbers, she explained, refer to the number of 23andMe customers who claimed that all four grandparents came from a single group. Additionally, 23andme makes use of certain external data sets comprising 560 East Asians, for a total of 1368*. Which is more than a little weird, since people of European descent only make up about 10-20% of the world population, whereas Asians make up some 40%.
Note that the size of the 23andMe European set (6421 individuals) is about 800% that of Asians. The total European data set, including 23andme data plus the public set (rightmost column)has 6842, which is about 500% that of the total East Asian data set of 1368*. When I pointed this out to Mountain, she agreed it was a problem. “Absolutely. The truth is, this actually is from a couple of data sets frozen two to three years ago,” she said. “Our database has grown since then.”
Having old data is the kind of disclosure that would have been useful for 23andMe to mention in my report.
Mountain told me that “[23andMe co-founder and CEO] Anne Wojcicki is really focused on how to diversify,” but I wasn’t reassured by Mountain’s examples. She told me of a project called “Roots Into The Future*,” whereby 23andMe made a concerted effort to gather 20,000 African-American samples. That’s great news. But it didn’t answer my question. Especially since the numbers for users of Sub-Saharan African descent were also shockingly low. The 23andMe Sub-Saharan African sample size here is 228, which is about 2800% smaller than the European set. Based on the total data sets in the rightmost column (23andMe data plus public data set), the Sub-Saharan African sample size is 1100% smaller than the European set (621 versus 6842)*. And yet, the population of Sub-Saharan Africa is 1 billion, a figure that does not even include the 37+ million African-Americans, 30 million Afro-Caribbeans, and 5 million Sub-Saharan African immigrants in Europe, Asia, and elsewhere.

I pointed out to Mountain that if 23andMe was so concerned about diversity, they could purchase or acquire data sets from outside the US. Like from Asia, for example. Was 23andMe at all interested in non-US DNA, I asked?
Mountain replied yes, but the example she gave made me wonder whether she was listening to me at all. “One of the studies [we’re using] is called ‘Peoples of the British Isles,’ which is data for 2-3,000 people all over the British Isles.” And off into the thicket we go…
Could the company be doing a better job with collecting ethnographic data? “Absolutely they could,” Wells said, “but it’s not their raison d’être.” Which, of course, is pharma and health research. Fair enough—it’s their money. But how about a disclaimer attached to the ancestry part of the report? Like, “for entertainment purposes only?” Because data based on 76 Koreans (or any other ethnic group) is definitely not worth potentially causing family discord or a blood feud. I don’t know whether the company understands the realities of deadly global ethnic tensions and the potential damage created by people’s trust in these reports.
However, I did learn this about myself:

*Editor’s Note: 23andMe’s program Roots Into The Future was originally identified as Roots of the Future. The sentence has been corrected. Additionally, 3 comparisons made in data set sizes have been revised to use the combined 23andMe+Public data set figures as seen in the screenshots above.