More and more of the things that set the internet on fire are of that species of charmingly moronic pairing of text and image that allows even the post-literate to feel like they have partaken of a shared cultural moment. And now, scientists are beginning to understand how the curiously addictive visual tropes known as “memes” are born, why they die, and whether or not it’s possible to predict which will “go viral” and be harvested by the night-soil merchants up at meme warehouses like Cheezburger.

More and more of the things that set the internet on fire are of that species of charmingly moronic pairing of text and image that allows even the post-literate to feel like they have partaken of a shared cultural moment. And now, scientists are beginning to understand how the curiously addictive visual tropes known as “memes” are born, why they die, and whether or not it’s possible to predict which will “go viral” and be harvested by the night-soil merchants up at meme warehouses like Cheezburger.
The internet, of course, was barely in its infancy when Richard Dawkins, a British evolutionary biologist, coined the term “meme” back in 1976. And he meant it as a much more nuanced concept, encompassing pretty much any idea that is good at propagating from one human brain to another—whether it is dialectical materialism or the tune to Happy Birthday.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
But Dawkins was deliberate in his comparison of memes to genes. Like the molecular units of inheritance, memes “reproduce” by leaping from one mind to another, “mutate” as they are re-interpreted by new humans, and can spread through a population. The internet has radically accelerated the spread of memes of all kinds; but it has also led to the rise of a specific kind of meme, the kind encapsulated by a phrase or a picture. And importantly for scientists, the life of a such a meme is highly measurable.
New research from Michele Coscia of Harvard University goes so far as to suggest a decision tree—which is sort of like a flow chart—that can show at any given point in an internet meme’s life how likely it is to go viral. In order to generate this chart, Coscia tracked 178,801 variants of 499 memes, all gathered from what is arguably the internet’s biggest clearinghouse for memes, Quickmeme.

This decision tree is a bit challenging to parse, but here goes. The number at the top, 35.47%, is the total proportion of all the memes Coscia analyzed that were “successful.” By his definition, success meant receiving a high enough score on Memebase, where users can vote a meme up or down. (His threshold for “success” was necessarily somewhat arbitrary.)
Among these successful memes, an interesting phenomenon emerges. Those that hit an above-average peak of popularity at some point in their life were less likely, overall, to ultimately break the “success” threshold. Memes that were shared more consistently over time, rather than a great deal all at once, were more likely to ultimately rack up enough points.
If you think Nature is red in tooth and claw, you have yet to stare longingly at a website’s analytics dashboard, quietly willing an article you wrote to go viral. (Not that anyone at Quartz has ever done this.) In the attention economy, memes compete for a finite pool of attention, representing all the time everyone spends on the internet. Which means that for one meme to become popular, some other meme must pass into obscurity.
Coscia’s data crunching revealed that memes that were “more competitive” than others—that is, whose rise in popularity tended to correlate with the fall in popularity of other memes—were more likely to succeed overall.
Coscia identified a number of “meme organisms”—clusters of memes that tend to do well together. He doesn’t speculate about why, exactly, these memes’ fates seem to be linked together, but a look at meme cluster #45, consisting of two memes (the average number in a cluster was 4.8) suggests a strange sort of logic to their linkage.

Perhaps (this is my speculation) one interpretation of meme organisms is that certain memes seem to capture the zeitgeist. Thus, memes could have seasonal patterns, or even follow the anxieties and fads of the day, as suggested by trends in the news. Or perhaps memes that remind you of one another do well because they feed off one another’s attention. Just as genres emerge in music, literature and art, so too in internet memes.
Coscia notes that most previous research on how things go viral has sought to map the social interconnections of those who are sharing content. Thus, studies of how news is shared on, say, Twitter $TWTR seek to map who are the most influential sharers of information in any given news cycle.
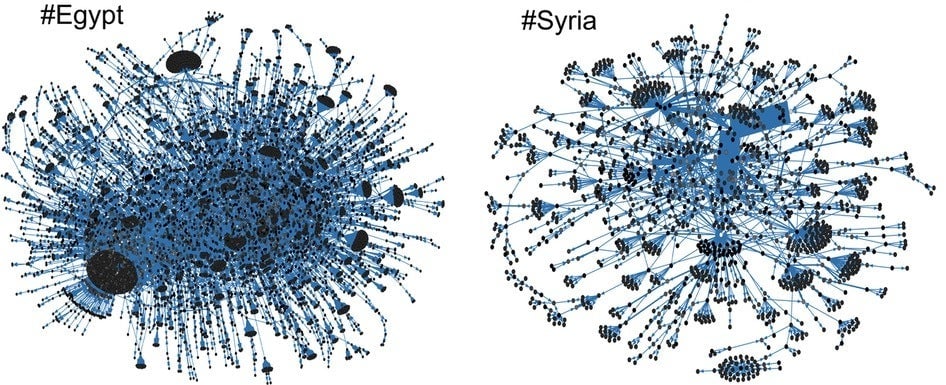
But Coscia completely ignored who was sharing which memes—all of his data came entirely from the scores that memes receive on Quickmeme—and yet he was still able to discern patterns about which kind of memes would go viral. It’s not surprising that the underlying structure of the internet, a given website, and the human brain should all have an effect on making some things more likely to spread than others, but in his attempt to qualify the characteristics of this collective system, Coscia showed that memes can have intrinsic characteristics that make them more likely to succeed. Granted, these qualities aren’t apparent until a meme has already begun to spread, but once identified, they help predict how well it might do at some point in the future.
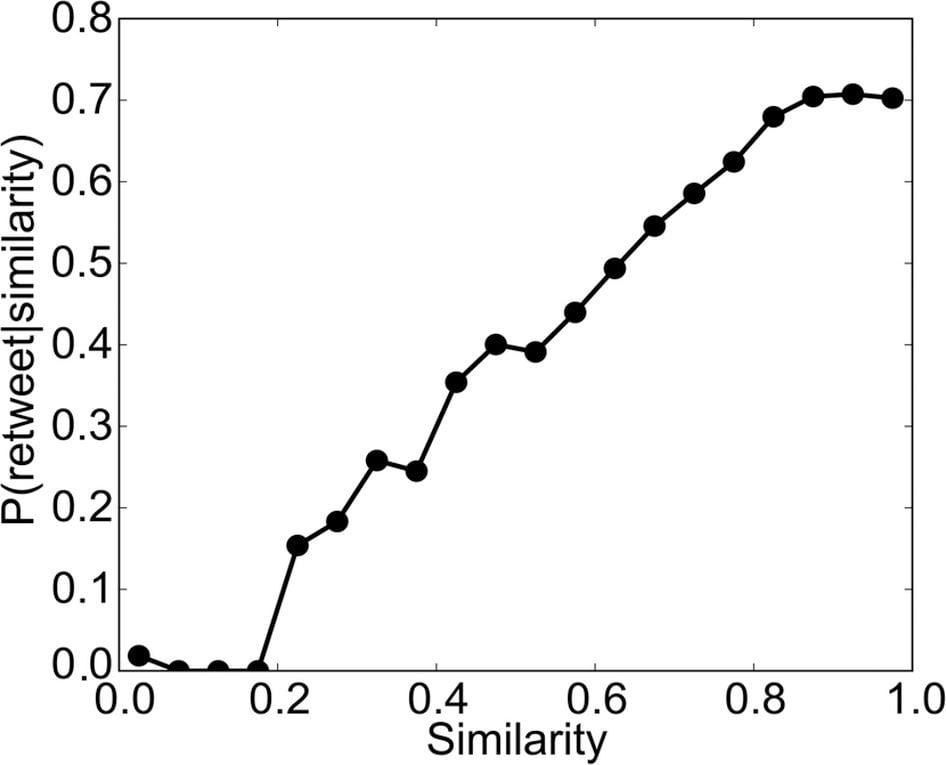
Past research about memes shows two things that should surprise no one, but are worth emphasizing: If you can figure out what someone is interested in, you can predict how likely she is to share a piece of content. And the more similar a piece of content is to what she has shared before, the more likely she is to share it. In other words, affinity groups rule the web.
Also, memes have a half-life. They become popular, and then, taken as a whole, they are consumed and then tossed on the scrap-heap of history.
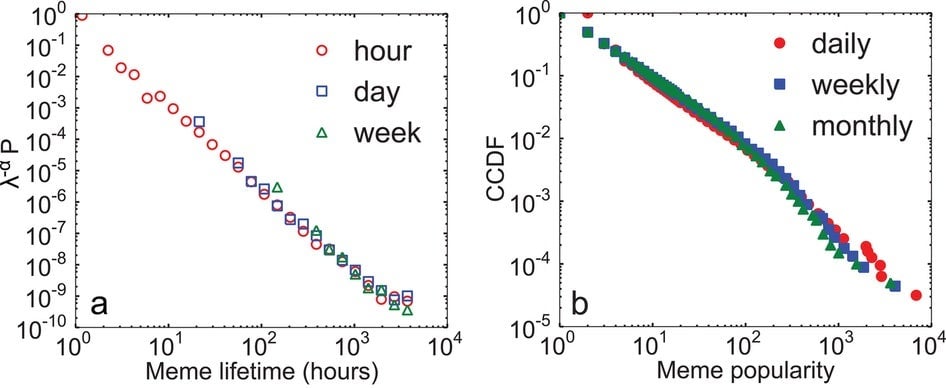
Attempts to predict what will go viral on the internet are based on the past behavior of a meme. As Coscia emphasizes in his work, no one has yet to rigorously demonstrate, in advance, why any particular type of content goes viral. This sort of prognostication remains an art rather than a science.