So much of what we do today leaves a digital trail: we swipe credit cards, check in on Foursquare, tweet links and thoughts, connect on LinkedIn, shop on our iPads, and more. Every bit of that information is being stored—but by whom?
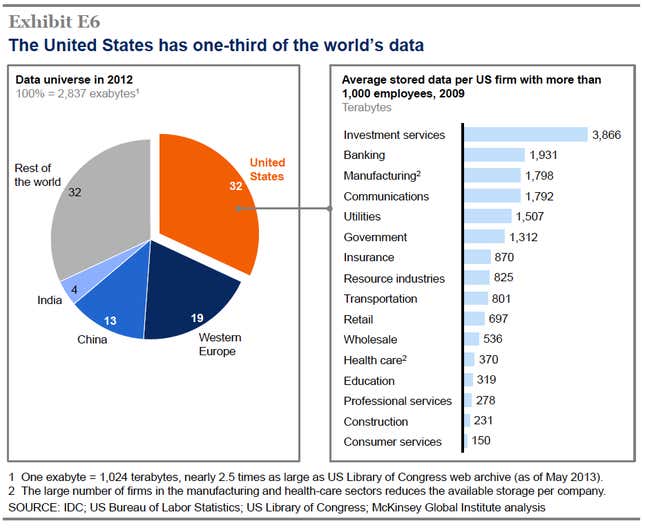
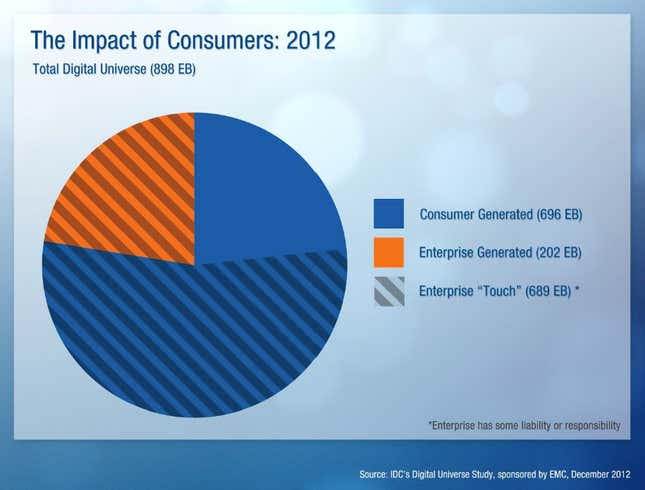
The US alone is home to 898 exabytes (1 EB = 1 billion gigabytes)—nearly a third of the global total. By contrast, Western Europe has 19% and China has 13%. Legally, much of that data itself is property of the consumers or companies who generate it, and licensed to companies that are responsible for it. And in the US—a digital universe of 898 exabytes (1 EB = 1 billion gigabytes)—companies have some kind of liability or responsibility for 77% of all that data. That’s the shaded “enterprise touch” data in the chart below.
The most recent data on who’s storing that data are from 2009, and published in a report released today by the McKinsey Global Institute. Although this may have changed some in the last few years, it’s our best guess yet about who actually holds onto a lot of US data.
Investment services companies (which are non-bank finance-related companies) are far and away the biggest hoarders of data; in 2009, big financial services firms on average stored 3,866 terabytes of data. That was almost double the amount of data banks stored. Manufacturing and communications firms also had lots of data. Perhaps surprisingly, communications firms—including social media, which the Census Bureau lumps in with other traditional media firms—rank lower on average in the sheer volume of information they store.
Aside from debates about protecting this data—yes, the NSA may be snooping on you—the problem for the US, according to McKinsey economists, is that its businesses don’t actually utilize all this data well. Industries are only slowly realizing the potential of collecting data and processing it to use to their benefit. Many are grappling with how to process an overwhelming volume of stuff from numerous data sources quickly and accurately.
Doing so could reap big rewards. Better number-crunching in retail and manufacturing alone, McKinsey analysts believe, could boost US GDP by $325 billion by 2020. Retailers that can better plan consumer behavior can make their inventory more efficient. Manufacturers that are better informed about the costs of materials, labor and the health of equipment can make more accurate projections about how much money they’ll need to invest to make something, or whether they should or shouldn’t build a plant.
The biggest obstacle to capitalizing on “big data” is a lack of workers skilled in how companies can break the data down. From the report:
By 2018, the United States will face a shortage of up to 190,000 data scientists with advanced training in statistics and machine learning—and this specialty requires years of study. More broadly, an additional 1.5 million managers and analysts will need enough proficiency in statistics to ask the right questions and consume the results of the analysis of big data effectively.