After crossing the $1 billion dollar mark this weekend, Black Panther is increasingly emerging as a blockbuster with unforeseen impact. Thrown almost as a challenge to known assumptions about what makes a great superhero movie, the filmmakers were surprisingly rewarded for their on-screen courage. In addition to attracting thousands of movie watchers, the movie is also drawing the positive attention of critics, and finally gaining the professional recognition it deserves.

After crossing the $1 billion dollar mark this weekend, Black Panther is increasingly emerging as a blockbuster with unforeseen impact. Thrown almost as a challenge to known assumptions about what makes a great superhero movie, the filmmakers were surprisingly rewarded for their on-screen courage. In addition to attracting thousands of movie watchers, the movie is also drawing the positive attention of critics, and finally gaining the professional recognition it deserves.
For much of the audience, the diversity of the cast did not go unnoticed and made the critical and popular praise received for the film feel even more significant. However, seeing their dark skin tones and natural hairstyles, I couldn’t help but wonder—would commercial computer vision models be able to recognize actors in the same way the critics do?
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
When we discuss mainstream bias, we often think of discrimination in the context of media representation and mass incarceration, housing permits and credit scores. However, quite recently, it’s been discovered that there exists an invisible strain of demographic bias lurking within the algorithms making the automated decisions that feed into those outcomes. Termed “machine bias” from the seminal work by ProPublica, this form of encoded prejudice is particularly likely in machine-learning models used in artificial-intelligence software.
If machine learning is about learning patterns from data, what happens if the data becomes untrustworthy? For instance, a model can be taught to recognize a pattern, like a face by being trained on many examples of faces. But if these image examples lack diversity, then the model can easily adopt the biases of its training set.
A recent example of this, uncovered in Joy Buolamwini and Dr. Timnit Gebru’s Gender Shades study, was recently highlighted by the New York Times. Using a purposefully diverse set of 1,270 faces, they were able to evaluate how well the commercial models from IBM $IBM, Face++ and Microsoft $MSFT could predict gender for different subgroups. The Gender Shades analysis found that the same models that predicted gender at effectively 100% accuracy for lighter-skinned males predicted at less than 70% for darker females. This non-uniform performance across demographic categories is often measured and critiqued in the machine-learning fairness community as a lack of demographic parity, something Joy herself refers to as the “coded gaze” — when only certain populations are recognized or seen due to bias in a machine-learning model.
Given the explosive divergence of Black Panther characters from the narrow representation we often see in mainstream media, how well could commercial computer-vision models detect the faces and estimate the demographics of its cast? It was an interesting case study of the impact of the Coded Gaze on the individual, and a peek into how commercial visual-recognition models handle these unique cases.
The actors’ age at the time of the photoshoot was taken as demographic information, and we allowed a +/- two year uncertainty for age predictions. We assembled the results from five major mainstream image classifiers, compressing our findings into “Coded Gaze” scorecards for each of the nine major Black Panther characters.
A summary of the breakdown by company and demographic subgroups is as follows, in the following tables.


As one can see, there’s a notable difference in accuracy between predicting the gender of the women of Wakanda versus the men in the film. While male gender predictions were universally correct, the female characters were misclassified on several occasions, by a variety of models.
The lowest score was earned by Okoye, who was not detected by Clarifai and Kairos, and received just 6/18 Coded Gaze points on her individual scorecard. This means her face was not recognized as such by the models, and thus was not even visible to the models. Given her unique hairstyle and darker skin, I suspected this outcome, as it was in line with my understanding of the effects of the coded gaze, in which models perform worse the further one escapes the narrowly defined female images we often observe in mainstream media.
In fact, many of the women were often misclassified or, in Okoye’s case, completely overlooked by the models. Female characters in general performed at accuracy levels 20% below that of male characters, when comparing their complete Coded Gaze scores.
This case study also revealed the challenge of age prediction, with the vast majority of predicted ages being completely misclassified. The most extreme case was the character Ramonda, whose age was grossly underestimated , at times, by 40+ years.
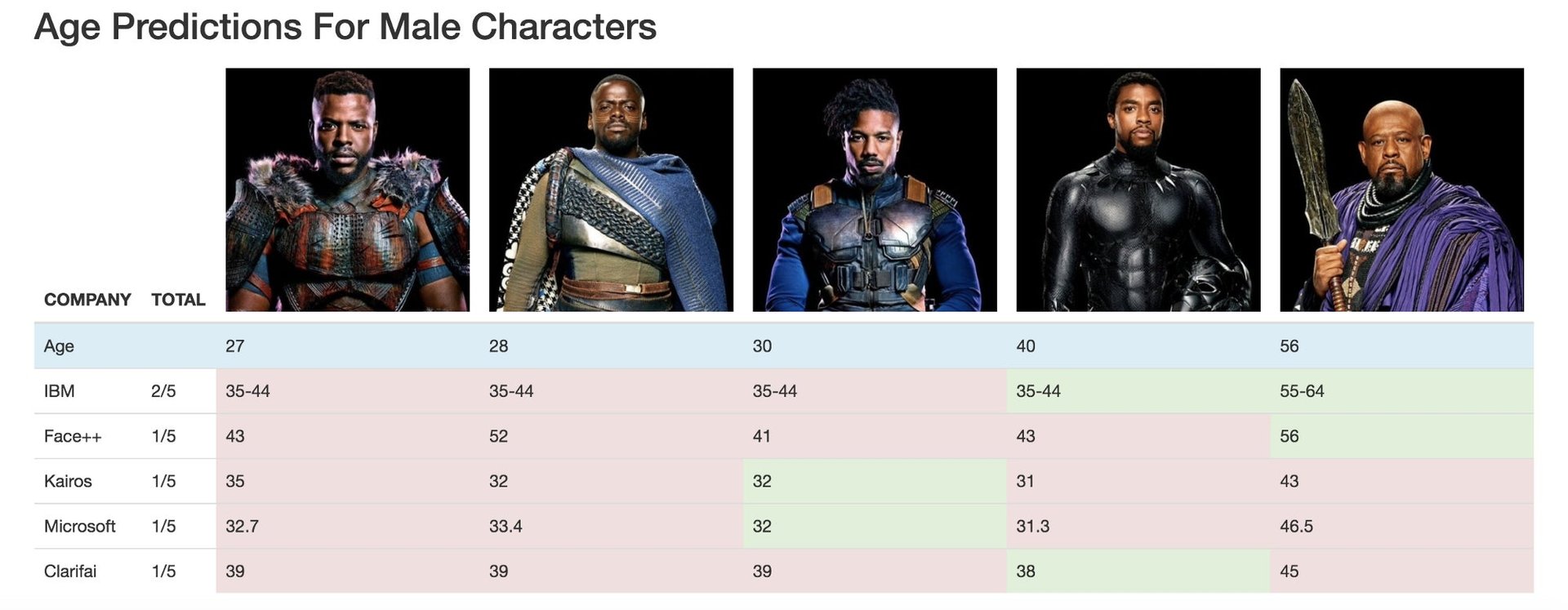

External factors aside — the objective difficulty of age prediction based on facial features, combined with the undoubted use of makeup and Angela Bassett’s agelessness —this example does brings into question the differences in the visual markers that we use to define age across different demographic groups, and highlights this area as a potential focus for future investigations.
Although not shown, ethnic predictions were almost universally accurate across the board, with only a handful of exceptions for certain female characters. For more details on this, one can look into individual scorecards.
While this small sample does not give sufficient evidence to make generalizations, walking through individual examples helps us illustrate the personal impact of the coded gaze and highlight the often unconsidered limitations of known and celebrated black-box models for certain demographic subgroups.
Although, there has been some movement to make improvements in response to Gender Shades, case studies like this are a great launch pad for questioning the inclusiveness of the data that is used to both train and test these models, and bring much-needed attention to the issue.
Given that, across all companies, the overall average accuracy of the cast is at less that 75%, then it raises a point of serious concern. Who are these models really working for, and what do we need to consider with regards to representation in the data being fed into these tools?
What these examples embody is a present-day celebration of diversity at odds with the limitations of the technology we build, which seems paradoxically anchored in the past.
All around us, we see movements rising up for the protection of visible minorities, and yet our commercial systems can easily fail to detect and correctly identify a given diverse example. When we train our models with an incomplete vision of what the world is, neglect our responsibilities as tech creators, let limitations of available media restrict the scope of who we serve, and, most pointedly, exclude certain types of individuals from the industry and thus the conversation, we end up with this Coded Gaze.
And under this gaze, even when we as a society decide to recognize a diverse group , our models continue to struggle to do the same.
It’s thus more important than ever to keep ourselves accountable to biases that might infiltrate our technology, as not to impede on the progress of our real-world superheroes, as women and as people of color, aiming to create and hoping to be acknowledged by our human and automated systems for the reality of who they are.
This analysis is based on results from online demoes of all the companies tested. The capabilities may have changed since the test performed in February 2018.
This case study is not a comparison of each company’s objective performance and should not be taken as such. The goal is not to pit companies against each other, and the focus of this case is really not about the companies at all. What this article is actually about is the individuals involved and those they represent — those that are in general misclassified due to their lack of representation in mainstream and corporate datasets. If anything, it should serve as a call to action to anyone involved in this industry and inspiration to dig into this issue with further intensity.