Geoffrey Hinton is a legendary computer scientist. When Hinton, Yann LeCun, and Yoshua Bengio were given the 2018 Turing Award, considered the Nobel prize of computing, they were described as the “Godfathers of artificial intelligence” and the “Godfathers of Deep Learning.” Naturally, people paid attention when Hinton declared in 2016, “We should stop training radiologists now, it’s just completely obvious within five years deep learning is going to do better than radiologists.” The US Food and Drug Administration (FDA) approved the first AI algorithm for medical imaging that year and there are now more than 80 approved algorithms in the US and a similar number in Europe.
Geoffrey Hinton is a legendary computer scientist. When Hinton, Yann LeCun, and Yoshua Bengio were given the 2018 Turing Award, considered the Nobel prize of computing, they were described as the “Godfathers of artificial intelligence” and the “Godfathers of Deep Learning.” Naturally, people paid attention when Hinton declared in 2016, “We should stop training radiologists now, it’s just completely obvious within five years deep learning is going to do better than radiologists.” The US Food and Drug Administration (FDA) approved the first AI algorithm for medical imaging that year and there are now more than 80 approved algorithms in the US and a similar number in Europe.
Yet, the number of radiologists working in the US has gone up, not down, increasing by about 7% between 2015 and . Indeed, there is now a that is over the next decade.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
What happened? The inert AI revolution in radiology is yet another example of how AI has overpromised and under delivered. In books, television shows, and movies, computers are like humans, but much smarter and less emotional. The less emotional part is right. Despite our inclination to anthropomorphize computers (who can forget R2-D2 and C-3PO?), computer algorithms do not have sentiment, feelings, or passions. They also do not have wisdom, common sense, or critical thinking skills. They are extraordinarily good at mathematical calculations, but they are not intelligent in any meaningful sense of the word.
Radiology—the analysis of images for signs of disease—is a narrowly defined task that AI might be good at, but image recognition algorithms are often brittle and inconsistent. Only 33% of radiologists reported using any type of AI in 2020, according to a recent study from the American College of Radiology.
Furthermore, only 40 of the more than 80 radiology algorithms currently cleared by the FDA, along with 27 in-house tools, were utilized by respondents. Only 34% of these were used for image interpretation; the other applications included work list management, image enhancement, operations, and measurements. The bottom line: only about 11% of radiologists used AI for image interpretation in a clinical practice. Of those not using AI, 72% have no plans to do so while approximately 20% want to adopt within five years.
The reason for this slow diffusion is poor performance. Only 5.7% of the users reported that AI always works while 94% reported inconsistent performance.
AI’s inconsistent performance is emphasized by other experts, both in radiology and across healthcare. In a recent interview, AI guru and Coursera founder Andrew Ng said that, “Those of us in machine learning are really good at doing well on a test set, but unfortunately deploying a system takes more than doing well on a test set.” He gave an example:
when we collect data from Stanford Hospital, then we train and test on data from the same hospital, indeed, we can publish papers showing [the algorithms] are comparable to human radiologists in spotting certain conditions. It turns out [that when] you take that same model, that same AI system, to an older hospital down the street, with an older machine, and the technician uses a slightly different imaging protocol, that data drifts to cause the performance of AI system to degrade significantly. In contrast, any human radiologist can walk down the street to the older hospital and do just fine. So even though at a moment in time, on a specific data set, we can show this works, the clinical reality is that these models still need a lot of work to reach production.…All of AI, not just healthcare, has a proof-of-concept-to-production gap.
The American College of Radiology survey agreed with Ng: “A large majority of the FDA-cleared algorithms have not been validated across a large number of sites, raising the possibility that patient and equipment bias could lead to the inconsistent performance.” We can see the impact of the proof-of-concept-to-production gap in other applications, but under different names. A study published in Sloan Management Review reported that, “A good rule of thumb is that you should estimate that for every $1 you spend developing an algorithm, you must spend $100 to deploy and support it.”
What is behind the poor performance of AI in radiology and in other imaging applications? Humans can see things for what they are. When we see a wagon or a picture of a wagon, we recognize what physicist and author Douglas Hofstadter calls its structural essence: a rectangular box, wheels, and a handle. It can be of various sizes, made of various materials, or painted different colors, but we still recognize it as a wagon. We can look at it from many different angles, but we still recognize it as a wagon. It may be partly obscured by some other object, but we still recognize it as a wagon.
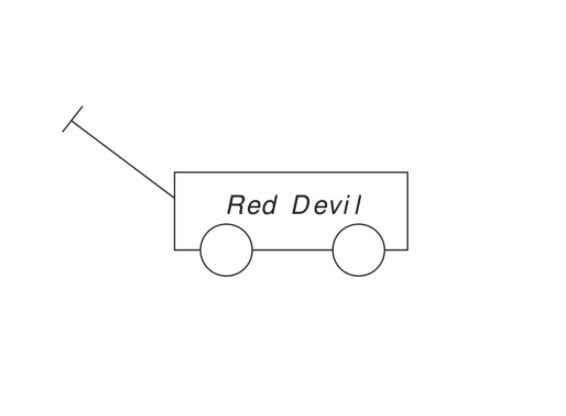
Not so with AI algorithms, which input pixels and create mathematical representations of those pixels—what Turing Award winner Judea Pearl calls “just curve-fitting,” or finding mathematical equations that fit a set of data without any consideration of what the data represent. AI algorithms are trained by being shown many, many pictures of wagons and the label “wagon.” When an algorithm is shown a new picture, it curve-fits the pixels and looks for a mathematical match in its database. If it finds a good enough match with the wagon pixels it has been trained on, it returns the label wagon though it might as well be nogaw since the algorithm has no idea what the label means.
If the new wagon picture is a different size, texture, or color; or viewed from a different angle; or partly obscured, the AI algorithm may flop. This brittleness is the basis for those Captcha tests where users are asked to prove they are not algorithms by clicking on the rectangles that contain pictures or cars, traffic signals, and so on.
When one of the authors tested the Clarifai deep neural network (DNN) image recognition program with the wagon image shown below, the program was 98% certain that the image was a business. The Wolfram Image Identification Project misidentified the wagon as a badminton racket. When the wagon color was changed to red, it was misidentified as a cigar cutter. When the red wagon was put on a 45-degree incline, it was misidentified as a paper clip.
The CLIP algorithm from Open AI, a startup founded by Elon Musk and the provider of the now infamous GPT text creation system, operates a bit differently. It requires users to help the program by submitting a small number of proposed labels, one of which is correct. Despite this artificial and extremely helpful hint, when the algorithm chose from wagon, sign, goal posts, and badminton racket, it gave probabilities of 0.03, 0.14, 0.80, and 0.03, respectively (with 1.0 being fully confident). When the algorithm chose from wagon, cigar cutter, paper clip, and badminton racket, the probabilities were 0.12, 0.64, 0.09, and 0.14, respectively. In each case, the probabilities changed if the spelling badminton racquet was used and depended on whether goal posts was entered as one word or two and singular or plural. The probabilities also fluctuated if the wagon was a different color or was put on an incline.
The CLIP landing page has a scan of a brain and the labels healthy brain and brain with tumor. When these labels were used with the wagon pictures, the algorithm was 76% sure that the white wagon was a healthy brain, and 80% sure the red wagon was a healthy brain.
How could AI mistake a wagon for a badminton racket, paper clip, or brain? How could it change its mind if the wagon is a different color, if racket is spelled differently, or if goalpost is two words? Image-recognition algorithms are fragile because they curve-fit pixel patterns instead of recognizing and understanding entities. Here, they do not know what makes a wagon a wagon (the box, wheels, and handle) and cannot distinguish between important features and superficial details.
Given the challenges for AI in distinguishing between a wagon, badminton racket, paper clip, and brain, it is not surprising that AI interpretations of medical images are fragile, and that physicians are reluctant to rely on AI for radiology and other life-of-death decisions.
A 2019 survey found that only one-third of hospitals and imaging centers report using any type of AI “to aid tasks associated with patient care imaging or business operations,” A just-published study of hundreds of machine-learning algorithms for using chest scans to detect COVID-19 found that 85% “failed a reproducibility and quality check, and none of the models was near ready for use in clinics.”
The slow diffusion of AI in radiology hasn’t diminished Geoffrey Hinton’s deep optimism for deep learning. Undaunted by the setbacks, he recently proclaimed, “Deep Learning will do everything,” which reminds us of investor Ed Yardeni’s quip about predicting the stock market: “If you give number, don’t give a date.”