
At this very moment in Serengeti National Park, Tanzania, more than 200 hidden cameras are snapping photos day and night, capturing the secret lives of the Serengeti’s most elusive animals.
And, at this very moment, one of those cameras is probably getting chomped by a hyena. Such are the perils of being a camera trap in our Snapshot Serengeti survey.
The Serengeti is an incredibly diverse and dynamic ecosystem, famous for its high density of large carnivores and the annual migration of 1.6 million wildebeest and zebra.
When we found ourselves with even more pictures than there are participants in that annual migration, we knew we had to figure out a way to classify and use all this information we were collecting. We turned to citizen scientists as a way to work through all these images and extract the valuable information they contain. Within three days of asking for the public’s help, we successfully processed an 18-month backlog of more than one million classifications.
With the help of about 30,000 volunteers who identified the images via the website Snapshot Serengeti, the first three years of data have been classified, catalogued and now published through Nature’s new journal, Scientific Data. This is the largest data set of its kind and would never have been possible without the help of the general public.
As a graduate student in Ecology, Evolution, and Behavior at the University of Minnesota, I set 225 cameras to study how large carnivores shared the landscape with each other and their prey. Over the last five years, these remote, automatic cameras have captured more than two million images and more than 40 different animal species, providing an unprecedented look into the savanna wildlife ecology.

Camera traps have revolutionized ecology and conservation research by providing a relatively low-cost method to monitor many different species across large areas. Triggered by a combination of heat and motion, when an animal walks by, these cameras snap a picture.
Every photograph has a location, date, and time; by combining the information in these images, researchers can paint a picture of how many animals there are, where they are, and what they’re doing. With enough cameras and enough pictures, researchers can answer questions about how many different species interact to drive the incredibly complex dynamics of a natural ecosystem.
But “enough” data to answer complex ecological questions often means “too much” data for researchers to process. And, despite enormous recent advances in computer vision research, this type of complex pattern recognition remains something that the human brain is uniquely good at.




This is precisely the problem that I was facing: despite relentless vandalism by curious hyenas and elephants, the camera traps were capturing more pictures than I could possibly process alone, or even with a small army of undergraduate volunteers. So fellow ecologist Margaret Kosmala and I partnered with the world’s largest and most successful citizen science platform, The Zooniverse, to build Snapshot Serengeti.
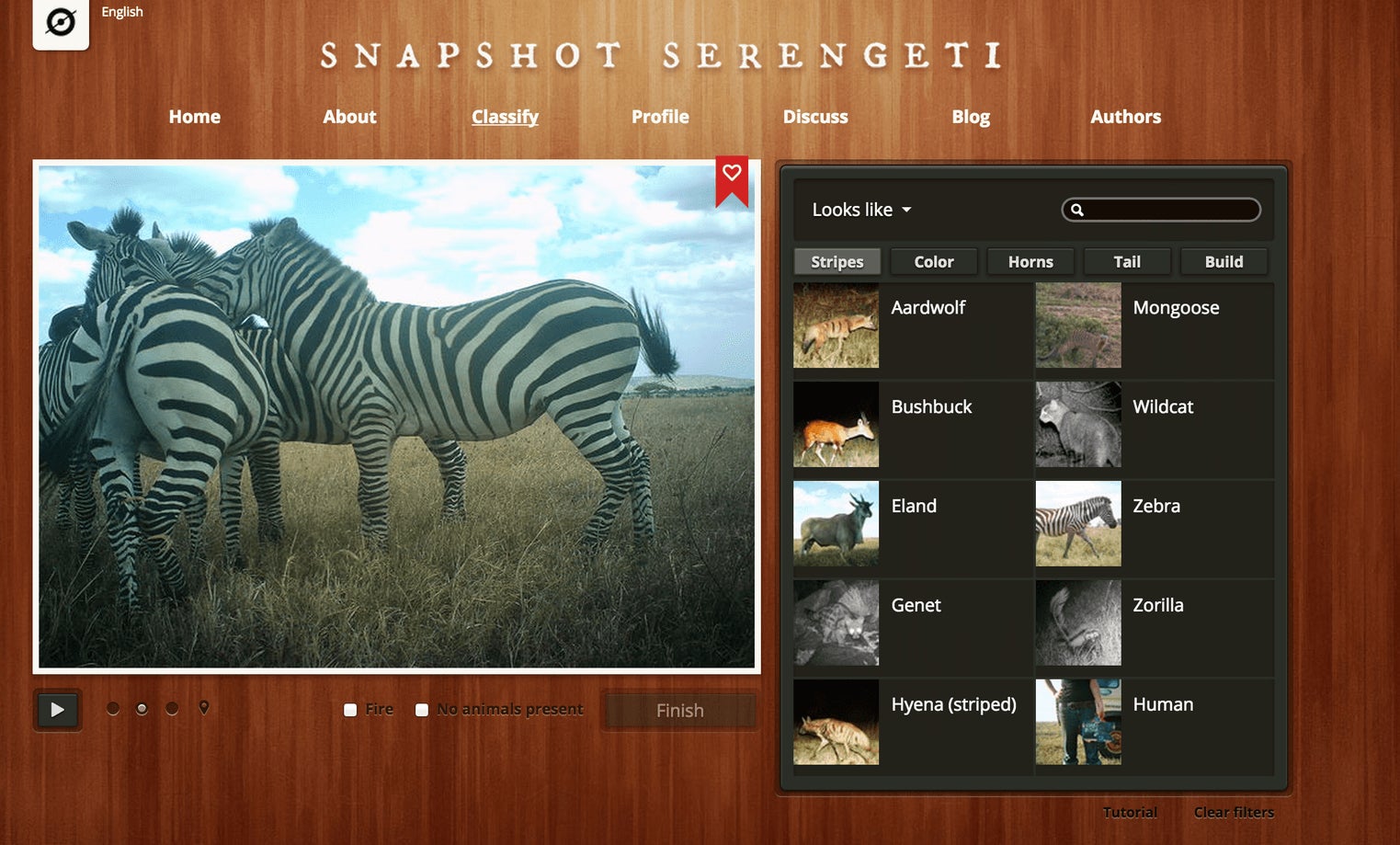
Like all Zooniverse projects, Snapshot Serengeti was designed to let anyone—not just experts—make valuable and reliable contributions. We asked users to identify and count the species that they saw in each photo. Volunteers could filter animals by body shape, color, pattern, even tail shape to narrow in on the best possible answer. On the discussion forums, they could talk with each other and with us about what they were seeing and why it mattered. This could all be done in their pajamas on the couch, since all they needed was an internet connection.
As it turns out, there are a lot of people interested in contributing to science. It took only three days for volunteers on the website to work through our year-and-a-half backlog of data.
Since we launched it in 2012, volunteers continue to classify Snapshot Serengeti photos faster than we can bring them back from the field.
More importantly, though, volunteers on Snapshot Serengeti produce incredibly reliable classifications. By sending each image to multiple volunteers, we were able to aggregate across their answers to produce a final “consensus answer.”

We used a plurality algorithm—which is pretty much just a slightly fancy majority vote. When we compared the consensus citizen scientist answers to a set of more than 4,000 expert-classified images, volunteers were right 97% of the time. On top of that, we can look at the disagreement in the raw answers to predict whether any given image is easy or hard, and thus whether the answer is likely to be right or wrong. That lets us target expert effort on just those 3% of images that really need it.
The data produced by Snapshot Serengeti have already led to new insights about the Serengeti ecosystem. For example, these cameras revealed how lions and cheetahs divide up the same high-value real estate hot spots on a moment-to-moment basis—providing a possible explanation for their curious coexistence. By integrating camera trap data with satellite imagery, we are starting to explore the hidden drivers of the wildebeest migration, and to study how prey animals balance the need for food with the relentless risk of being eaten.
Snapshot Serengeti has enormous potential for widespread use beyond the ecological questions that drove its design. We hope that the published data set, freely and publicly available on the Dryad Digital Repository, will be used by researchers across disciplines—whether they are studying rare species or training computers to automatically detect and identify species.
Snapshot Serengeti’s success demonstrates the enormous potential for citizen science to help researchers tackle bigger questions than ever before. Camera traps provide a way to collect the ecological data necessary to answer bigger questions about the world around us, but citizen science is what provides a way to turn this data into new scientific knowledge, enabling research at a scope and scale otherwise impossible.