For many people, working with error-ridden spreadsheets is a way of life. This takes on added meaning for genomics researchers, who study the building blocks of life. It turns out that their work, too, is rife with dodgy spreadsheets.

For many people, working with error-ridden spreadsheets is a way of life. This takes on added meaning for genomics researchers, who study the building blocks of life. It turns out that their work, too, is rife with dodgy spreadsheets.
A new paper has revealed the vast extent of errors in published genomics research, which is down to an unfortunate quirk of Microsoft $MSFT Excel. A trio of scientists in Australia scanned 7,500 Excel files with gene lists accompanying 3,600 papers in 18 journals over a 10-year period. One-fifth of the files had easily identified errors, which is “quite striking and a little bit embarrassing,” says Mark Ziemann of the Baker IDI medical research institute in Melbourne, one of the paper’s co-authors.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
What happened? By default, Excel and other popular spreadsheet applications convert some gene symbols to dates and numbers. For example, instead of writing out “Membrane-Associated Ring Finger (C3HC4) 1, E3 Ubiquitin Protein Ligase,” researchers have dubbed the gene MARCH1. Excel converts this into a date—03/01/2016, say—because that’s probably what the majority of spreadsheet users mean when they type it into a cell. Similarly, gene identifiers like “2310009E13” are converted to exponential numbers (2.31E+19). In both cases, the conversions strip out valuable information about the genes in question.
This setting can be temporarily switched off in Excel and other applications, and isn’t activated automatically in Google $GOOGL Sheets, the researchers say. The conversion snafu only affects around two dozen genes, out of some 30,000 in the human genome, Ziemann says. “It’s still annoying,” he adds.
For scientists who use these data files as a starting point for other studies, the two-dozen renamed genes won’t be included in their analysis. (The paper’s authors created a script that will screen spreadsheets for common renaming errors.) Although heavy analysis tends to be done with more sophisticated software packages like Perl, Python, and R, the common way to shuttle these gene lists between labs and bioinformatics services is via spreadsheets. “It’s just not suited for genomics research,” Ziemann says.
“I just use Excel to draw graphs and stuff and have generally been happy with it,” says Daniel Turner of Oxford Nanopore, a genetic technology company. “It helps that I’ve got bioinformaticians in my team to do the hard stuff.”
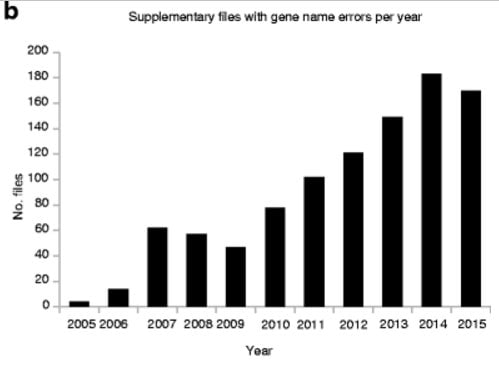
The thing is, there’s no excuse for data experts to be missing these errors with such regularity in the first place. A paper back in 2004 first highlighted the pitfalls of gene-name conversions in spreadsheets, and yet the problem has only grown since then.
It raises uncomfortable questions about the peer-review process at prestigious scientific journals, Ziemann says. Supplementary data files are becoming more common features of published research, and “my feeling is that the supplements aren’t given as much scrutiny as the main articles,” he notes. Experts in biology may be comfortable examining the science in the text of submitted papers, but not sifting through tens of thousands of rows in spreadsheets looking for errors in gene symbols.
Still, although a one-fifth error rate may sound like a lot, it’s not nearly as bad as in the business world, where some studies suggest that as many as 90% of spreadsheets in use at companies contain errors of one sort or another (pdf). It’s still noteworthy, however, that in a way the malign mutations of Microsoft Excel can be said to reach all the way down to the molecular level.
With additional reporting by Mun-Keat Looi