Stealing an AI algorithm and its underlying data is a “high-school level exercise”
Billions of dollars are being poured into building sophisticated artificial intelligence algorithms. But they could all be snatched away if even a tiny door is left open.

Billions of dollars are being poured into building sophisticated artificial intelligence algorithms. But they could all be snatched away if even a tiny door is left open.
Researchers have shown that given access to only an API, a way to remotely use software without having it on your computer, it’s possible to reverse-engineer machine learning algorithms with up to 99% accuracy. In the real world, this would mean being able to steal AI products from companies like Microsoft and IBM, and use them for free. Small companies built around a single machine learning API could lose any competitive advantage.
Moreover, after copying the algorithm, the researchers were also able to force it to generate examples of the potentially proprietary data from which it learned. If the algorithms are built on user data, any of that information would be up for grabs as well.
“In hindsight, it was just blatantly obvious,” said Thomas Ristenpart, co-author of the research and associate professor at Cornell Tech. “It’s kind of a high-school level exercise, that you can put together a list of high-school level equations and solve for the function.”
Despite the modesty in describing the general concept, the attacks are more complex than what you would see in a high school math classroom—dozens to tens of thousands of data points are needed to rebuild a working model of a hidden algorithm.
Google, Amazon, and Microsoft allow developers to either upload their algorithms to their cloud or use the cloud company’s proprietary AI algorithms, both of which are accessed through APIs. Uploading the algorithm makes sense because the data and heavy lifting stays on the cloud company’s server. And making proprietary algorithms available in this way lets companies charge for their use without having to hand over the code.
Think about making a call to a machine learning API as texting a friend for fashion advice.
“Does this shirt match these pants?” you might send, with a photo. The friend would send back, “Yes, 100% positive.”
Ask a question, and you get back an answer and an indication of how confident they are about it. Most APIs work the same way: send some specific data, and get an answer with a confidence value.
Now imagine you were to send your friend thousands of messages about which shirt matches with which pants, and whether they like certain scarves, and how many colors you can pull off wearing at the same time. After driving your friend insane, you would get a pretty clear idea of their fashion sense, and how they would pick clothes given your wardrobe. That’s the basis of the attack. Researchers would make standard requests from the AI algorithm thousands of times through the API, and piece together how it thought about a problem.
The researchers found that the complexity of the algorithm mirrored how hard it was to steal. Simple yes-or-no algorithms, which can be used to predict whether a tumor is malignant or mortality rates from sepsis, can be copied in just 41 queries, less than $0.10 under Google’s payment structure. Complex neural networks, like those used in handwriting recognition, on average took 108,200 queries, but achieved more than 98% accuracy when tested against the original algorithm.
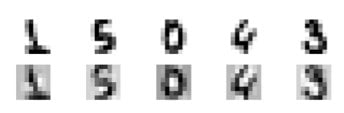
These attacks are limited by a few parameters: since APIs are typically monetized per use, this methods can get expensive over 100,000 uses, and also raise red flags with the service provider. Ristenpart says that deeper neural networks are vexing, especially if the approach is a conglomeration of a few different algorithms.
Once they had stolen an algorithm, the team was also able to reveal the data that had been used to train it. They tested this attack on a public data set of faces, often used for facial recognition, and found that every face could be reconstructed. The algorithm had memorized each face to such an extent that it could generate each person’s likeness. If a company were to train their algorithm on private data, like health records or their users’ information, there’s no guarantee it would be safe if the API were accessible.
Researchers revealed the potential for these attacks to Google and Amazon earlier this year, and told Quartz that the internet companies found the findings “interesting,” and would pass along the information to users.