In 2012, a comic made its way around the internet listing games on a scale of how close they were to being dominated by artificial intelligence. Checkers and tic-tac-toe had already been conquered; chess’s human champion had been dethroned, and IBM’s Watson had taken no prisoners on Jeopardy. The “Computers may never outplay humans” section still had its stalwarts: Calvinball—the game in Bill Waterson’s Calvin and Hobbes where the rules are made up on the fly—and Seven Minutes in Heaven. Just one step up, listed under “Computers still lose to top humans,” were Chinese game Go and American pastime poker.

In 2012, a comic made its way around the internet listing games on a scale of how close they were to being dominated by artificial intelligence. Checkers and tic-tac-toe had already been conquered; chess’s human champion had been dethroned, and IBM $IBM’s Watson had taken no prisoners on Jeopardy. The “Computers may never outplay humans” section still had its stalwarts: Calvinball—the game in Bill Waterson’s Calvin and Hobbes where the rules are made up on the fly—and Seven Minutes in Heaven. Just one step up, listed under “Computers still lose to top humans,” were Chinese game Go and American pastime poker.
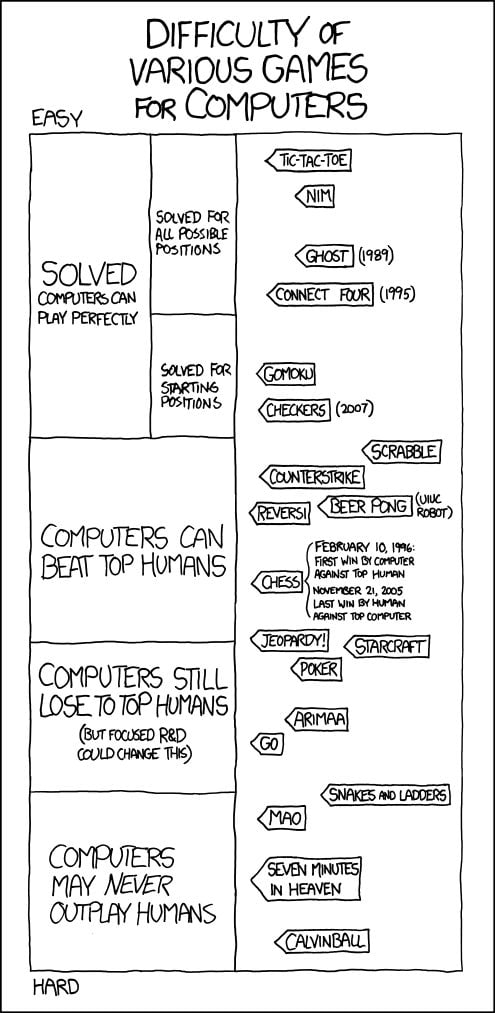
Fast-forward to January 30, 2017, at the Robots vs. Brains poker tournament in Pittsburgh, Pennsylvania. Ph.D candidate Noam Brown is sitting next to a professional poker player closing out his 20th day of losing to Libratus, a poker-playing bot that Brown co-created at Carnegie Mellon University. As the game progresses, Brown is lightheartedly fielding questions on a Twitch livestream, where a viewer reminds him of that 2012 comic. “Yeahhh,” Brown laughs, pulling the image up in front of him. “I think all of these need to be shifted up.”
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
A few minutes later, after almost three weeks and 120,000 hands of poker, Libratus finished trouncing its human opponents—four of the world’s best professional poker players—in No Limit Texas Hold ‘Em. The margins were not slight. Were the games not played with imaginary money, the pros would have lost a combined $1.7 million dollars.

Libratus’ poker victory arrived a little more than nine months after AlphaGo, an AI out of London-based DeepMind, beat Go champion Lee Sedol in a series of seven matches. AlphaGo’s win was the first spotlight event for AI beating humans in a game of our own design since chess savant Garry Kasparov’s groundbreaking 1997 loss to IBM’s DeepBlue. An AI may still be far from figuring out the arbitrary world of Calvinball, but beating humans at challenges involving changing, uncertain situations is exactly what Libratus is designed for. Thrives on, even.
Libratus has played trillions of simulated poker hands, but the game is hardly its ultimate goal, just as Go isn’t the ultimate application of DeepMind’s software, and IBM’s AI research didn’t end with Kasparov’s loss. The algorithms behind Libratus were applied to the card game, but the AI itself is built to efficiently manage any kind of negotiation, and to dismantle any opponent that stands in its way. Brown’s AI could be used in situations like those faced by CEOs, politicians, and even intelligence agencies. We could begin to rely on mechanical brains to dictate foreign policy, or to tell us the best strategy for hostage negotiation. It just starts with poker.

“I think of [poker] like a benchmark, much like chipmakers have their benchmarks,” says Tuomas Sandholm, the CMU professor who is overseeing Libratus and co-created it with Brown. “There’s no ambiguity in the rules, so you could say technique A is better than technique B, or technique A is better in these conditions, or in these ways.”
Sandholm has been working on building algorithms that thrive in uncertainty for 27 years. His work in automating negotiations has been applied to the United Network for Organ sharing, optimizing the process of pairing donated kidneys with recipients in two-thirds of US transplant centers and saving thousands of lives in the process. His 1997 startup, CombineNet, applied that work to the auctioning process, and has managed $60 billion in spending.
Sandholm believes the idea powering Libratus is even more powerful.
When thinking about any game, there’s an assumption that a perfect strategy exists. This perfect strategy, called the Nash Equilibrium by game theorists, would mean that no other set of moves could serve the player better. It’s the objective pinnacle of play.
Libratus’ goal is to find that perfect strategy. For No Limits Texas Hold’em, you can imagine this strategy as the core of the Earth: We know it’s there. We can reason what it should look like and what it’s made of, but we can’t get there to actually study it. Now think of Libratus as the world’s biggest drill.
The algorithm doesn’t function like most of the other AI you’ve heard about. It’s not a deep neural network—the AI behind tools like Facebook $META’s automatic photo-tagging and Google $GOOGL’s Inbox Smart Reply. Before the tournament, Libratus had never seen a human play poker. The AI has three modules, each performing a different task. Module 1 learns the game of poker, trying to find strategies that work for every situation. Module 2 is the decision-maker for each action the bot takes during a hand. And Module 3 is updated consistently, recording and folding the new information from each move into the system.

In order to beat anyone at poker, Libratus had to first learn the game. Much like a human player, it did that by practicing against an opponent to learn which strategies work and which don’t. Unlike a human, it played trillions of games over 15 million simulated hours, all against a clone of itself. This is called reinforcement learning: The algorithm slowly learns from its own experiences, rather than by analyzing external data like games played by humans.
The first game Libratus played was completely random. Bet, fold, raise, check, call—they all meant the same thing. But after each hand, Libratus analyzes its strategy against the strategy of its opponent. Because the reward in poker is extremely easy to measure—money—the bot learns after each round which action could have made more money, and stores that strategy for the next time the same situation arises. The actions taken that don’t end in winning are “pruned;” they’re not even considered the next time the bot finds itself in that situation, which saves the AI precious processing time.
That kind of efficiency is crucial: Libratus is playing trillions and trillions of hands, and No Limit Texas Hold’em has… no limit, meaning an infinite amount of betting can happen.

To save the supercomputer from needing to calculate for an infinite number of possibilities, Brown and Sandholm made a simpler, slightly less complex version of the game. All the rules were the same, but instead of being able to bet in $1 increments, the bot could only bet in specifically designated amounts like $200, $250, $300, $400, and $500. To the machine, $290 was the same as $300; the system would just round up. Brown calls this technique “action abstraction.”
They used a similar trick for the cards themselves. Instead of calculating every potential hand, Brown set similar poker hands to be seen as identical to the AI. There’s not much difference between a Queen-high flush and a King-high flush, for example, so it’s rare the bot would need to know the difference. It would just need to know how to act when presented with a royal-high flush. Teaching the AI to think in broad strokes paid off: Brown says that the card abstractions alone reduced the complexity of the game by a factor of 100,000. If either card or action abstraction were twice as large, the AI would require twice as much time and memory to compute.

Knowing that, it doesn’t really seem like Libratus is playing poker at all, but rather a shadow of the game; or as Brown calls it, an abstraction. He makes no equivocation that the first module isn’t really playing poker. It might have calculated a Nash Equilibrium, but it’s for a much simpler game.
While the first module’s job is to be certain of what’s happening on the poker table, the second module deals with the uncertainty of the opponent’s hand. Module 1 might sound like other AI, roughly learning how to do something over trillions of iterations. But Module 2, the ability to work in uncertain situations, is what sets Libratus apart.
Poker involves a lot of uncertainty. In other games, like chess, there are no secrets. The only factors that can influence the game are openly displayed on the board, meaning every variable is known. Even though a queen can be used in millions of strategies, it’s known to exist in a certain place at a certain time. If the queen were invisible or hidden on the board, a chess-playing bot would have to consider millions of alternate realities based on the potential position of the queen, and the resulting strategies that would spawn from each possible position.
In Texas Hold’em, two of your opponent’s cards are obscured, making 169 potential hands to consider. This is what game theorists call an “imperfect knowledge” game, where you don’t know certain information about your opponent’s position.
To crack this problem, Libratus’ second module is called the end-game solver—and it’s every bit as devastating as it sounds. While the first module is in charge of strategy on the pre-flop and flop—before and as a new hand is dealt—the end-game solver takes over from the turn to the end of the hand.
The end-game solver first recalculates the game using no card or action abstraction; it needs to be as precise as possible. It then uses estimates from the first module’s trillions of hands to guess what the opponent probably has. By using the vast amount of data gathered by the first module, the end-game solver runs through estimates of the most probable hands of the opponent, solving for what they should have rather than what they actually do. Every time the opponent makes a move, the end-game solver recalculates, folding the new information into its strategy. This recursive method of computing is able to chop off entire trees of possibilities, based on the probability an opponent would make a certain decision with a certain hand.

Brown says that the end-game solver is what makes Libratus so strong. It’s also what could make it useful in a board room, or a war room. The software looks at its situation, and tries to predict the best move for nearly every potential way the game could play out, based on games it’s played before. When the opponent makes a move, the calculations are made again, with the opposition’s decision informing a narrower set of potential outcomes. In poker, that means maximizing the chance of winning while not knowing the opponent’s cards. In the real world, it could mean knowing when a foreign power is bluffing about military strength.
It also makes Libratus bold. While artificial intelligence as we know it today has no wants, desires, or human motivations, the construction of an AI is based on its application. That leads Libratus to act a certain way while playing. For instance, it doesn’t care about the competition in which it plays. It won’t be careful to save money, and it doesn’t keep in mind how much it’s up or down on the scoreboard. All it knows is the hand it’s playing, and a desire to win the most money regardless of the risk. If Libratus has a 10% chance of winning $20,000 against a 90% chance of winning nothing or a guaranteed $1,999, it will always take the 10% risk.
“The bot is fearless,” Brown says. “Humans don’t approach the game that way because even though they might know it is the right thing to do, a part of them is afraid and will hold them back.”
It’s worth noting that Libratus’ approach only works at scale. The AI was specifically built to play a poker competition of 120,000 hands, during which one big win can outstrip even a dozen tiny losses. On the competition’s final day, for example, Daniel McAuley was down on one table and up on the other. He slowly won small pot after small pot on his losing table; over 20 or so hands, down $10,000 became down $4,000, which turned into a little less than $2,000 above.
The reversal of fortune was swift. Within seconds, McAuley was down $4,000 again, then down $8,000. Libratus was brutally effective, its impact evident in the nearly imperceptible grimace that flashed across McAuley’s face.
Libratus’ first two modules are what make it strong, but Module 3 is what makes it smarter over time. Initiated once the AI began to play against humans, this part of Libratus runs each night, analyzing the three bet sizes it gauged to be most important based on what the humans bet the most. It allows the AI to learn.
Case in point: During the tournament, the poker professionals figured out that betting in odd numbers would mess up the AI, causing it to respond strangely. They repeatedly took advantage of that weak spot —betting $333 on every good hand, for instance—effectively shooting up a flare over the hole in the machine’s knowledge. The next day the flaw was gone. It wasn’t that Libratus was learning anything it couldn’t have from the first module; Module 3 just let it fill in the gaps more quickly.
By the time the players realized that the machine was onto them and starting coordinating their bets, it was too late. “Over time the holes became so small,” Brown says. “They were not able to effectively exploit them, and their situation became hopeless.”
