The poetically named “random forest” is one of data science’s most-loved prediction algorithms. Developed primarily by statistician Leo Breiman in the 1990s, the random forest is cherished for its simplicity. Though it is not always the most accurate prediction method for a given problem, it holds a special place in machine learning because even those new to data science can implement and understand this powerful algorithm.

The poetically named “random forest” is one of data science’s most-loved prediction algorithms. Developed primarily by statistician Leo Breiman in the 1990s, the random forest is cherished for its simplicity. Though it is not always the most accurate prediction method for a given problem, it holds a special place in machine learning because even those new to data science can implement and understand this powerful algorithm.
This was the algorithm used in an exciting 2017 study on suicide predictions, conducted by biomedical-informatics specialist Colin Walsh of Vanderbilt University and psychologists Jessica Ribeiro and Joseph Franklin of Florida State University. Their goal was to take what they knew about a set of 5,000 patients with a history of self-injury, and see if they could use those data to predict the likelihood that those patients would commit suicide. The study was done retrospectively. Sadly, almost 2,000 of these patients had killed themselves by the time the research was underway.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
Altogether, the researchers had over 1,300 different characteristics they could use to make their predictions, including age, gender, and various aspects of the individuals’ medical histories. If the predictions from the algorithm proved to be accurate, the algorithm could theoretically be used in the future to identify people at high risk of suicide, and deliver targeted programs to them. That would be a very good thing.
Predictive algorithms are everywhere. In an age when data are plentiful and computing power is mighty and cheap, data scientists increasingly take information on people, companies, and markets—whether given willingly or harvested surreptitiously—and use it to guess the future. Algorithms predict what movie we might want to watch next, which stocks will increase in value, and which advertisement we’re most likely to respond to on social media. Artificial-intelligence tools, like those used for self-driving cars, often rely on predictive algorithms for decision making.
Perhaps the most important, and most personal, application of these algorithms will be in health care. Algorithm-driven AI has the potential to radically transform how we diagnose and treat health problems from depression and the flu to cancer and lung failure. That’s why, though they can seem impossibly opaque, they’re worth understanding. And in fact, in many cases, they are relatively easy to understand.
The first step towards understanding the random forest is to understand decision trees. After all, what’s a forest if not a collection of trees?
Decision trees are based on the idea that we can make predictions by asking sets of yes-or-no questions. For example, in the case of suicide prediction, imagine we only had three pieces of information to use: whether a person was diagnosed with depression, whether they were diagnosed with bipolar disorder, and whether they visited the ER three or more times in the past year.
One of the cool things about decision trees is that, unlike other common prediction methods (such as statistical regression) they mirror how people actually make guesses. This makes them comparatively easy to explain. Since the researchers wouldn’t share actual data due to privacy concerns, here’s a hypothetical decision tree to predict whether a person committed suicide using the three pieces of information we have:
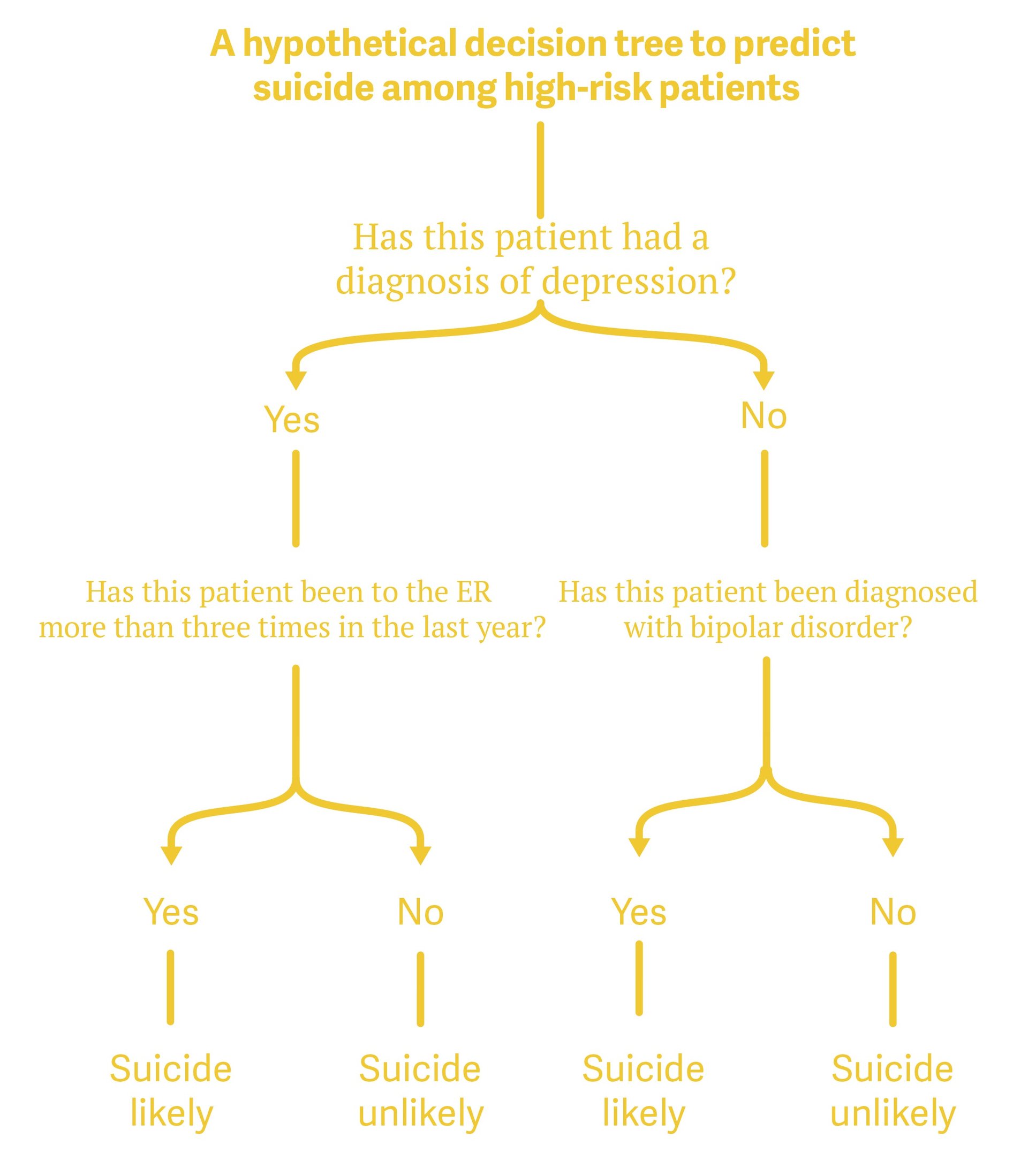
The splits in a decision tree like the one above are designed to minimize incorrect guesses. Though it’s possible for a human to calculate the correct splits, data scientists almost always let a computer do it. (If you want to learn more about how the those splits are derived, read this article).
The problem with decision trees is that you can’t make a good prediction with just one. You need to generate a bunch of different trees, and then take an average of the predictions from them all. This is where it gets a bit complicated: If you’re working with one dataset (in this example, depression/bipolar/ER visits), how can you make different trees out of it? Shouldn’t each tree be the same if you use the same data?
This leads us to one of the key insights of modern machine learning. One dataset can actually be made into many different datasets through resampling—creating new datasets that randomly exclude some of the data.
Let’s say the suicide-prediction researchers had a dataset of 5,000 people. To create a “new” dataset through resampling, the researchers would randomly select one person out of the full dataset of 5,000 people, 5,000 times. The reason the resulting dataset would be different from the source dataset is that the same person can be selected more than once. Due to the laws of probability, any given resampled dataset would only use around 3,200 of the 5,000 people in the source dataset; 1,800 people wouldn’t get randomly selected. With their resampled dataset, the researchers can then generate a new decision tree, which is likely to be a little different than the one using the original data.
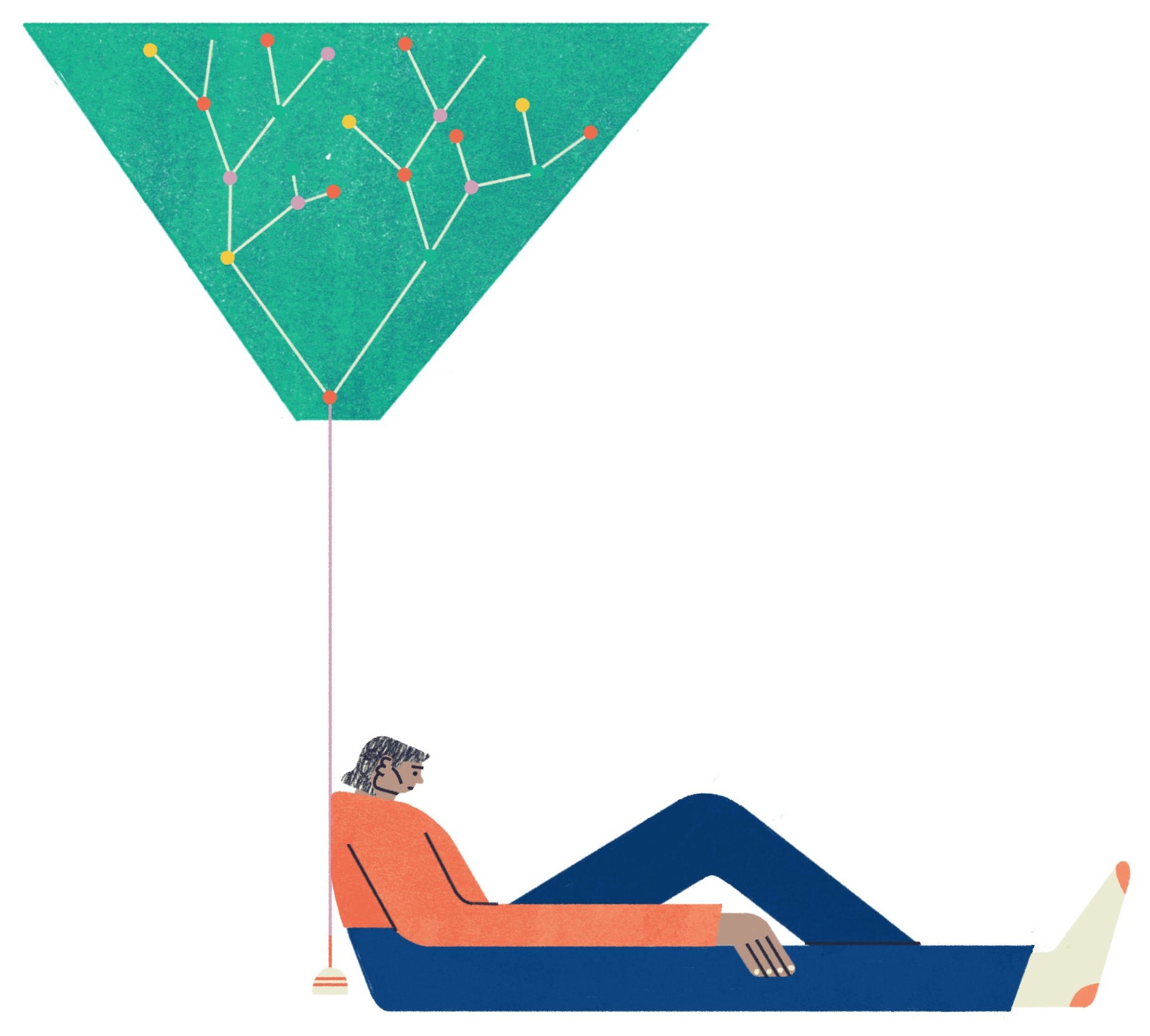
If the random resample happens to exclude unusual cases (AKA “outliers”), it will be more accurate than the original; if it happens to include all the outliers and leaves out some of the more typical cases, it might be less accurate. But the point is that you don’t make just one new tree. For a “random forest,” you make tons of them. The suicide-study researchers generated 500 different trees. Since the computer does all the work, sometimes researchers will make thousands of trees, or even millions. Usually though, 500 trees are enough—there’s a ceiling to how accurate a prediction forest can get.
Once the forest is generated, researchers typically take the average of all the trees to get a probability for the outcome they are studying. For example, if a 40-year-old man who makes $40,000 and has a history of depression was predicted to commit suicide in 100 of the 500 trees, then the researchers can say a person with those characteristics had a 20% chance of committing suicide.
To understand why resampling is important, imagine you were trying to predict the average person’s height based on age, sex, and income, and somehow professional basketball players LeBron James (6’8”/male/$35.65 million a year) and Kevin Durant (6’10”/male/$26.54 million a year) got into your sample of 100 people. A decision tree predicting height with these mega-rich basketball stars might erroneously lead to predictions that people who made over $25 million a year were always tall. Resampling ensures that the final analysis will include at least some decision trees where one or both of James and Durant are left out, and, therefore, provides a more realistic prediction. (For a more technical explanation of how resampling works in machine learning, try out this terrific interactive.)
We need to do one more thing to make our forest truly random.
Although the 500 trees made using the resampled datasets will vary somewhat, they won’t be all that different, since most of the data points will be the same in each resample. This leads us to the key insight of the random forest: If you limit the number of variables that you (or the computer) can choose from at any split, it’s possible to get distinct decision trees.
In the suicide-prediction study, the researchers had around 1,300 variables from which to make their prediction. In a typical decision tree, any of those 1,300 variables could be used to make a split in the tree. Not so for a decision tree in a random forest. Instead of all 1,300 variables, the computer is only offered a few to choose from, and those few are selected randomly.
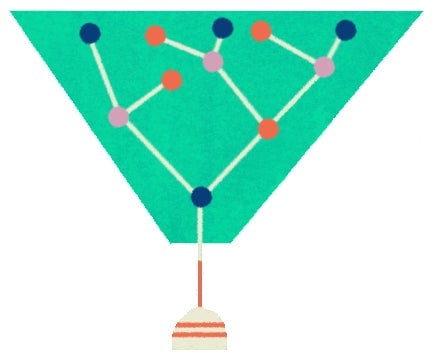
This randomization makes each tree in the random forest different—for the suicide study, some trees might include the variable for whether a person was diagnosed with depression, while another might not. In technical terms, we have “decorrelated” the trees. The final random forest prediction is made by averaging the predictions from these decorrelated trees—in the suicide-prediction study, 500 of them.
How does taking away variables from each tree, and making each individual tree less accurate, make the eventual prediction better? Consider again the example that attempts to predict height based on age, sex, and income in a 100-person dataset that, by chance, includes LeBron James and Kevin Durant. In this sample, any decision tree that uses income to predict height will guess that high-income people are extremely tall. If height is randomly left out of some decision trees, those trees will give a more accurate prediction for the typical person.
A good suicide-prediction algorithm should have two characteristics: One, it rarely predicts someone will commit suicide when he or she won’t. Two, it rarely misses identifying someone who does commit suicide. The random forest developed by the Vanderbilt and Florida State researchers performs pretty well on both accounts.
When tested against real-world outcomes, if the algorithm predicted that a person had a 50% chance or higher of committing suicides, 79% of the time they actually did. When the algorithm predicted the chances were less than 50%, it only happened 5% of the time.
A nice thing about random forests is that they give you a probability in addition to a yes-or-no prediction. Imagine the algorithm predicts that one person has a 45% chance of committing suicide, and another has a 10% chance. In both cases, the algorithm says the person is more likely to not commit suicide. But, for example, policy makers might want to build a program that targets all people the algorithm assesses to have a 30% or higher chance of committing suicide.
The random forest is only one of the many prediction algorithms that statisticians and computer scientists have developed. In some cases, it’s the best. (In our suicide-prediction study, for example, it was substantially more accurate than the performance of a simpler regression-based algorithm.) But in other contexts, other models might give better predictions. The most popular are support-vector machines and neural networks. Support-vector machines are useful when you have a lot of possible predictors, like when you are trying to predict the heritability of a disease based on genomic data. Neural-network algorithms tend to be very accurate, but are extremely slow to implement.
Unfortunately, the suicide-prediction study is an anomaly. Algorithms are most commonly used for targeted advertising and fraud detection, not improving public policy. There are some organizations, like the nonprofits DataKind and Bayes Impact, now trying to use algorithms for social good. DataKind, for example, developed predictive models for the John Jay College of Criminal Justice in New York City to help them identify which students were at risk of dropping out of college even though they were close to graduating. The algorithm was developed in 2017, and was based on more than 10 years of student data. The models will be used to target programs to assist these at-risk students.
These data models might seem obtuse and incomprehensible. They aren’t. If you have a little math acumen, you can learn how to understand and implement algorithms. The more people who learn these tools, the more likely we, as a society, are likely to apply them to a diverse set of problems, and not merely for commercial ends.
This story is one in a series of articles on the impact of artificial intelligence on health care and medicine. Click here to sign up to get alerted when new stories are published.