It happened last year for the first time: bot traffic eclipsed human traffic, according to the bot-trackers at Incapsula.

It happened last year for the first time: bot traffic eclipsed human traffic, according to the bot-trackers at Incapsula.
This year, Incapsula says 61.5% of traffic on the web is non-human.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
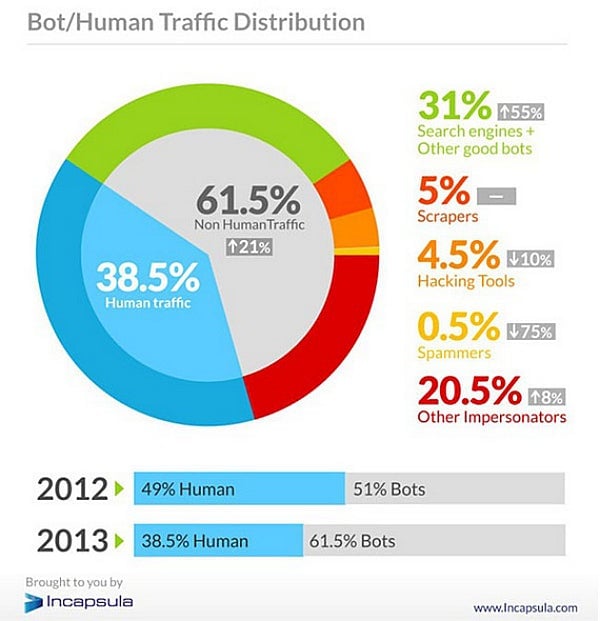
Now, you might think this portends the arrival of “The Internet of Things”—that ever-promised network that will connect your fridge and car to your smartphone. But it does not.
This non-human traffic is search bots, scrapers, hacking tools, and other human impersonators, little pieces of code skittering across the web. You might describe this phenomenon as The Internet of Thingies.
Because bots are not difficult to build. In fact, it’s so simple that a journalist (who has not learned to code) can do it.
I do it with a ($300) program called UBot Studio, which is an infrastructural piece of the botting world. It lets people like me program and execute simple scripts in browsers without (really) knowing any code.
Do you need 100 Hotmail accounts? I got you.
Perhaps you’d like some set of links autotweeted? I’m there.
You want to scrape a few numbers from a government website or an online store? Easy. It would take 10 minutes.
Or—and this is the one that gets to me—perhaps you want to generate an extra 100,000 page views for some website? So simple. A programmer friend of mine put it like this, “The basics of sending fake traffic are trivial.”
I’m going to tell you how here, even though I think executing such a script is highly unethical, probably fraud, and something you should not do. I’m telling you about it here because people need to understand how jawdroppingly easy it really is.
So, the goal is mimicking humans. Which means that you can’t just send 100,000 visits to the same page. That’d be very suspicious.
So you want to spread the traffic out over a bunch of target pages. But which ones? You don’t want pages that no one ever visits. But you also don’t want to send traffic to pages that people are paying close attention to, which tend to be the most recent ones. So, you want popular pages but not the most popular or recent pages.
Luckily, Google $GOOGL tends to index the popular, recentish stories more highly. And included with UBot are two little bots that can work in tandem. The first scrapes Google’s suggestions searches. So it starts with the most popular A searches (Amazon $AMZN, Apple $AAPL, America’s Cup) then the most popular B searches, etc. Another little bot scrapes the URLs from Google search results.
So the first step in the script would be to use the most popular search suggestions to find popularish stories on the domain (say, theatlantic.com) and save all those domains.
The first search would be “amazon site:theatlantic.com.” The top 20 URLs, all of which would be Atlantic stories, would get copied into a file. Then the bot would search “apple site:theatlantic.com” and paste another 20 in. And so on and so forth until you’ve got 1,000.
Now, all you’ve got to do is have the bot visit each story, wait for the page to load, and go on to the next URL. Just for good measure, perhaps you’d have the browser “focus” on the ads on the page to increase the site’s engagement metrics.
Loop your program 100 times and you’re done. And you could do the same thing whenever you wanted to.
Of course, the bot described here would be very easy to catch. If anyone looked, you’d need to be fancier to evade detection. For example, when a browser connects to a website, it sends a little token that says, “This is who I am!” And it lists the browser and the operating system, etc. Mine, for example, is, “Mozilla/5.0 (Macintosh; Intel $INTC Mac OS X $TWTR 10_8_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36”
If we ran the script like this, an identical 100,000 user agents would show up in the site’s logs, which might be suspicious.
But the user agent-website relationship is trust-based. Any browser can say, “I’m Chrome running on a Mac.” And, in fact, there are pieces of software out there that will generate “realistic” user agent messages, which Ubot helpfully lets you plug in.
The hardest part would be obscuring that the IP addresses of the visits. Because if 100,000 visits came from a single computer, that would be a dead giveaway it was a bot. So, you could rent a botnet—a bunch of computers that have been hacked to do the bidding of (generally) bad people.
Or you could ask some “friends” to help out via a service like JingLing, which lets people use other people on the network to send traffic to webpages from different IP addresses. You scratch my back; I’ll scratch yours!
But, if the botting process is done subtly, no one might think to check what was going on. Because from a publisher’s perspective, how much do you really want to know?
In the example I gave, no page has gotten more than 100 views, but you’ve added 100,000 views to the site as a whole. It would just seem as if there was more traffic, but it’d all be down at the bottom of the traffic reports where most people have no reason to look.
And indeed, some reports have come out showing that people don’t check. One traffic buyer told Digiday, “We worked with a major supply-side platform partner that was just wink wink, nudge nudge about it. They asked us to explain why almost all of our traffic came from one operating system and the majority had all the same user-agent string.”
That is to say, someone involved in the traffic supply chain was no more sophisticated than a journalist with 10 hours of training using a publicly available piece of software.
The point is: It’s so easy to build bots that do various things that they are overrunning the human traffic on the web.
Now, to understand the human web, we have to reckon with the logic of the non-human web. It is, in part, shady traffic that allows ad networks and exchanges to flourish. And these automated ad buying platforms—while they do a lot of good, no doubt about it—also put pressure on other publishers to sell ads more cheaply. When they do that, there’s less money for content, and the content quality suffers.
The ease of building bots, in other words, hurts what you read each and every day on the Internet. And it’s all happening deep beneath the shiny web we know and (sometimes) love.
Alexis Madrigal is a senior editor at the Atlantic, where he oversees the Technology Channel.