As human populations disperse, the separation leads to changes both in genes and in language. So if we look at human DNA and languages over time, we should find that they differ along similar geographic lines.

As human populations disperse, the separation leads to changes both in genes and in language. So if we look at human DNA and languages over time, we should find that they differ along similar geographic lines.
It’s an intuitive theory, but difficult to prove. That is, until researchers decided to match large collections of geographic, linguistic, and genetic data on hundreds of human populations worldwide.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
A new study (PDF), published in Proceedings of the National Academy of Sciences, quantifies the complicated relationship between these three factors. Researchers compared the geographic presence of two things in human populations across the world: alleles (trait-defining stretches of DNA) and phonemes (the distinct units of sound that make up spoken language).
This map shows a broad picture of the geographic spread of alleles and phonemes, according to the study’s findings. The arrows show that, in most parts of the world, languages and genes occupy the same areas and even appear to have traveled along similar trajectories.
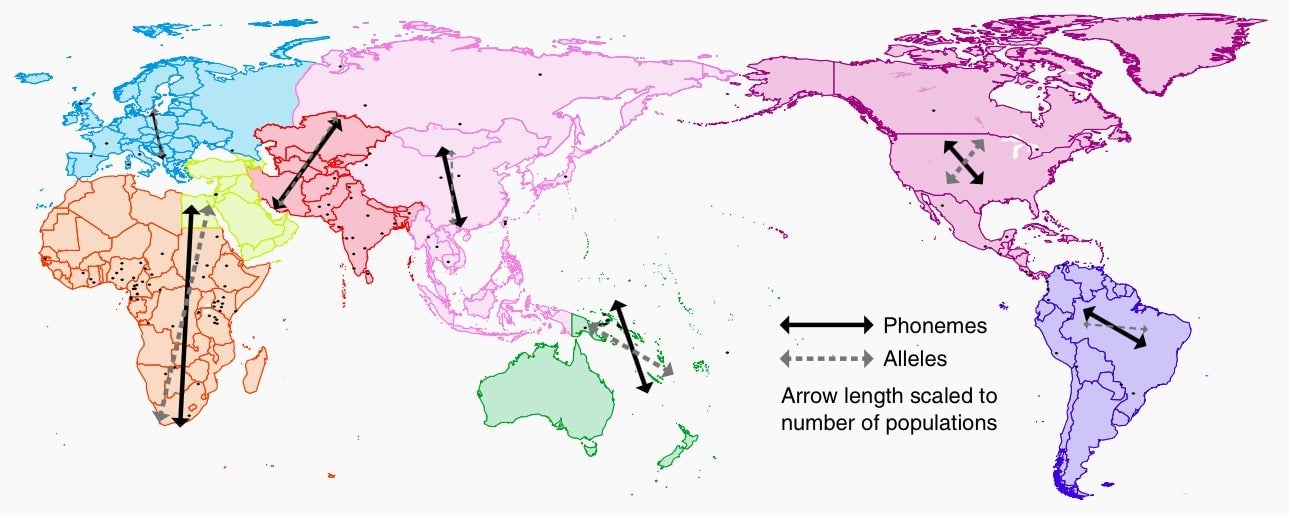
The scale of the research is impressive. “Our study directly compares the signatures of human demographic history in microsatellite polymorphisms from 246 worldwide populations and complete sets of phonemes for 2,082 languages,” the researchers write in their report. (Microsatellite polymorphisms are short DNA sequences that vary from person to person.)
These data have been available for some time, but never examined in the same place. “The thing we’ve done that no one else has is match worldwide genetic populations to their languages, so that you’re looking at a comparable set,” said Nicole Creanza of Stanford University, one of the report’s authors.
Using this new dataset and novel statistical techniques, the researchers were able to scratch an itch linguists and demographers have struggled to reach, showing that language and genes do in fact share similar geographic fault lines.
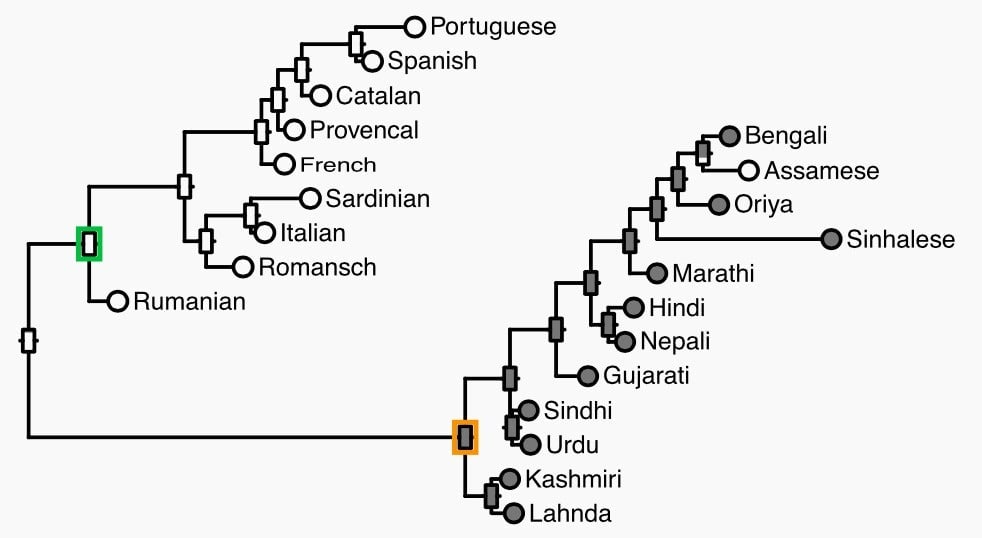
Here’s a more specific picture of what the results show. In the chart below, languages that are geographically near to each other are grouped into a tree structure. A gray circle marks the presence of a phoneme—/ʈ/, the voiceless retroflex stop—in that language. Only one language, Assamese, fully breaks from the trend in its geographic group.
This geographic relationship is no doubt compelling. But, as with any novel dataset, the analysis yielded several other thought-provoking results.
For example, according to the data, languages that are geographically close tend to share properties even if they are not linguistically related. “When two languages were geographically near, they tended to share more phonemes even if they were not closely related, suggesting a relationship between phonemes and geography both within and between language families,” the researchers wrote.
Another finding is related to isolation: When small populations separate from the gene pool, genetic diversity falls. In language, the opposite is true. The study shows that isolation leads to more diversity in phonemes. So while both are related to geography, biological and linguistic evolution operate at two very different speeds, with language being the much faster of the two.