
News bots will require a new approach to sensitive notions such as user profiling and opt-in systems. For both users and media, the potential upside is immense.
On Feb. 21, 2016, we looked at the virtues of conversational bots for the news media sector. These bots can become the badly-needed ingredient that triggers reader engagement and loyalty. If 2016 is to be the Year of Bots pundits promised, the news industry should not let this train pass.
When it comes to conversational bots, there is fantasy, and there is reality.
The far-fetched future is an artificial intelligence-augmented version of Apple $AAPL’s Siri. We’re not there yet. Today, iOS voice command is still crude and limited. It’s fine to send a text message or to ask for a weather forecast, but Siri is dumb; it barely learns from its numerous mistakes, and it doesn’t seem to accumulate any knowledge. “Siri is the opposite of a conversational bot,” said a computer scientist working on the issue. “It has the memory of a goldfish. It doesn’t have any clue to your most recent requests. It’s a ‘stateless’ thing unable to remember any piece of context.”
To morph into a real conversational bot, Siri would need to grasp the history, the “state” of its user, and then be supplemented with a thick machine-learning layer.
Google $GOOGL Now is of a different breed. It learns from the user’s behavior, knows about personal context such as travel habits, calendar, bookings, personal patterns, as well as outside environment parameters such as weather or traffic. Dynamically integrating these datasets significantly improves usability—to a point where it can become creepy. Also, Google Now works better in its text version than in its voice-activated option.
For the news industry, the situation is clear. In order to retrieve and distribute relevant information, a “NewsBot” should follow two paths: a predominantly text-based interface—since most of these services are aimed at mobile (who wants to speak to a smartphone riding a train, or in a café, seriously?)—and the integration of machine learning, natural language processing, and natural language-generation capabilities.
Here, two questions arise: How could the bot deal with the perimeter of news flows it will draw content from? How can it avoid generating “noise,” i.e. unwanted, or irrelevant pieces of information that clutter the system and eventually render it useless?
The answer lies in two principles: a variable perimeter and the use of in-depth profiling.
Let’s start with the profile.
First, no publisher or bot maker should expect users to manually customize their profile in order to enhance the system’s personalization. We already know that only a tiny percentage of users choose to customize their home page or their app. In itself, this is already a justification for the creation of news bots.
Therefore, the only option left is to use existing profiles.
Who knows the most about us? The big guys, of course. In that order: Facebook $META, Google, Microsoft $MSFT, Apple, Amazon $AMZN,Twitter $TWTR, LinkedIn, or even Pinterest $PINS:

Then, picture the following: in order to build an efficient system, NewsBot Corp. (a semi-fictitious name) wants to use personal information compiled by the big seven. The user agrees to let some of the internet giants feed her profile to NewsBot. This is only possible because she happens to trust both ends: the companies (at least some of them) that have compiled her profiles, and NewsBot.
The opt-in profile looks like this:
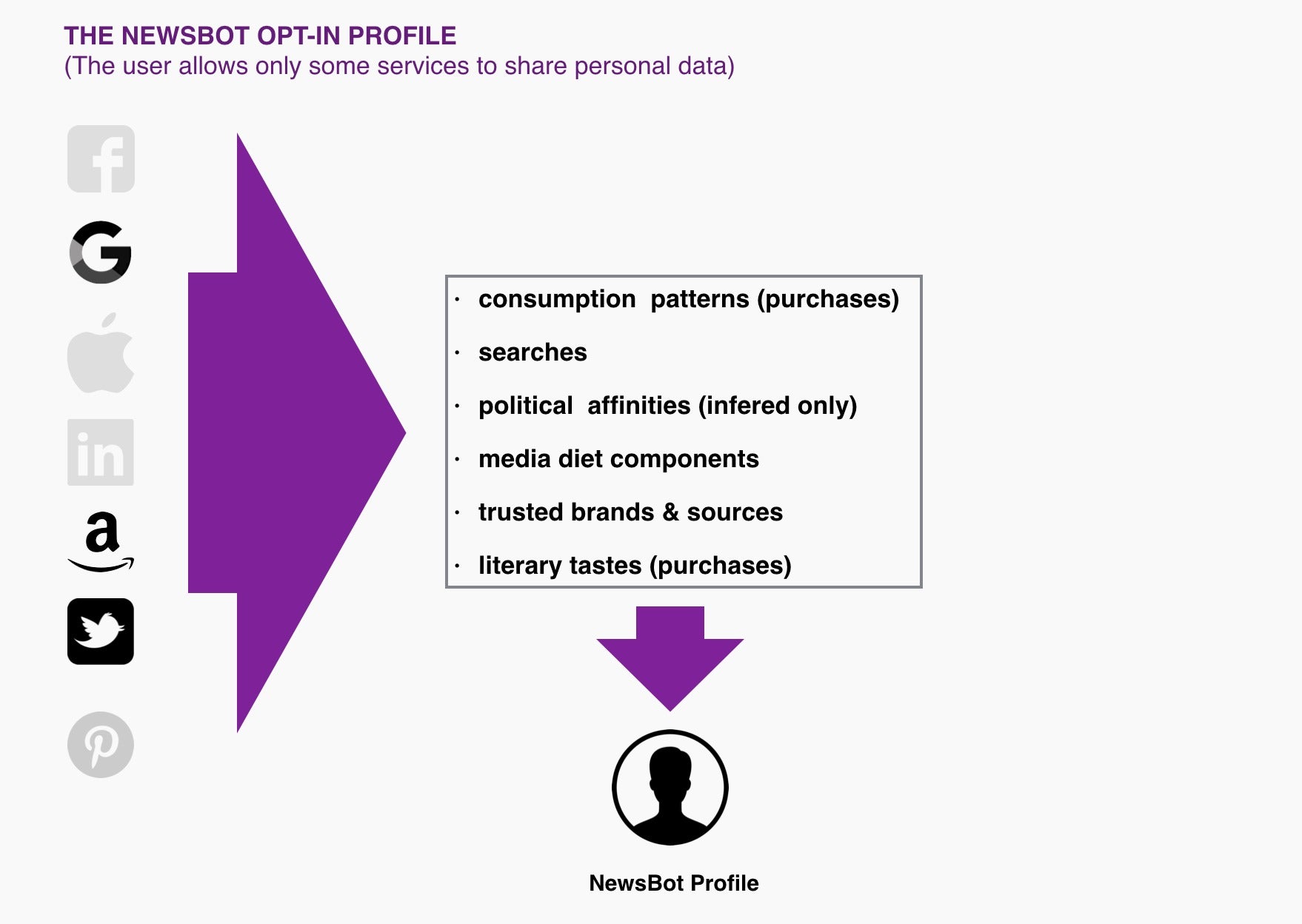
In this example, the user only allowed Google, Amazon, and Twitter to be used in her NewsBot profile.Why? Because, she believes that Google is fairly transparent about what it knows about her (she can download her data at any moment) and she doesn’t mind her past searches being used in her NewsBot profile, but she doesn’t want her Gmail data being used. For Amazon, she allows NewsBot to see her book purchases. As for Twitter, no sweat, her feed is already public. But, to her, Facebook data are too opaque, plus they might contain too many overly-personal details—and Mark Zuckerberg is known to look at the world as a vast digital rat lab to be algorithmically fed with Alice-in-Wonderland news streams.
Now, let’s look at the second principle, the perimeter.
Three layers must be considered:
Here is a possible rendering of the mobile interface:
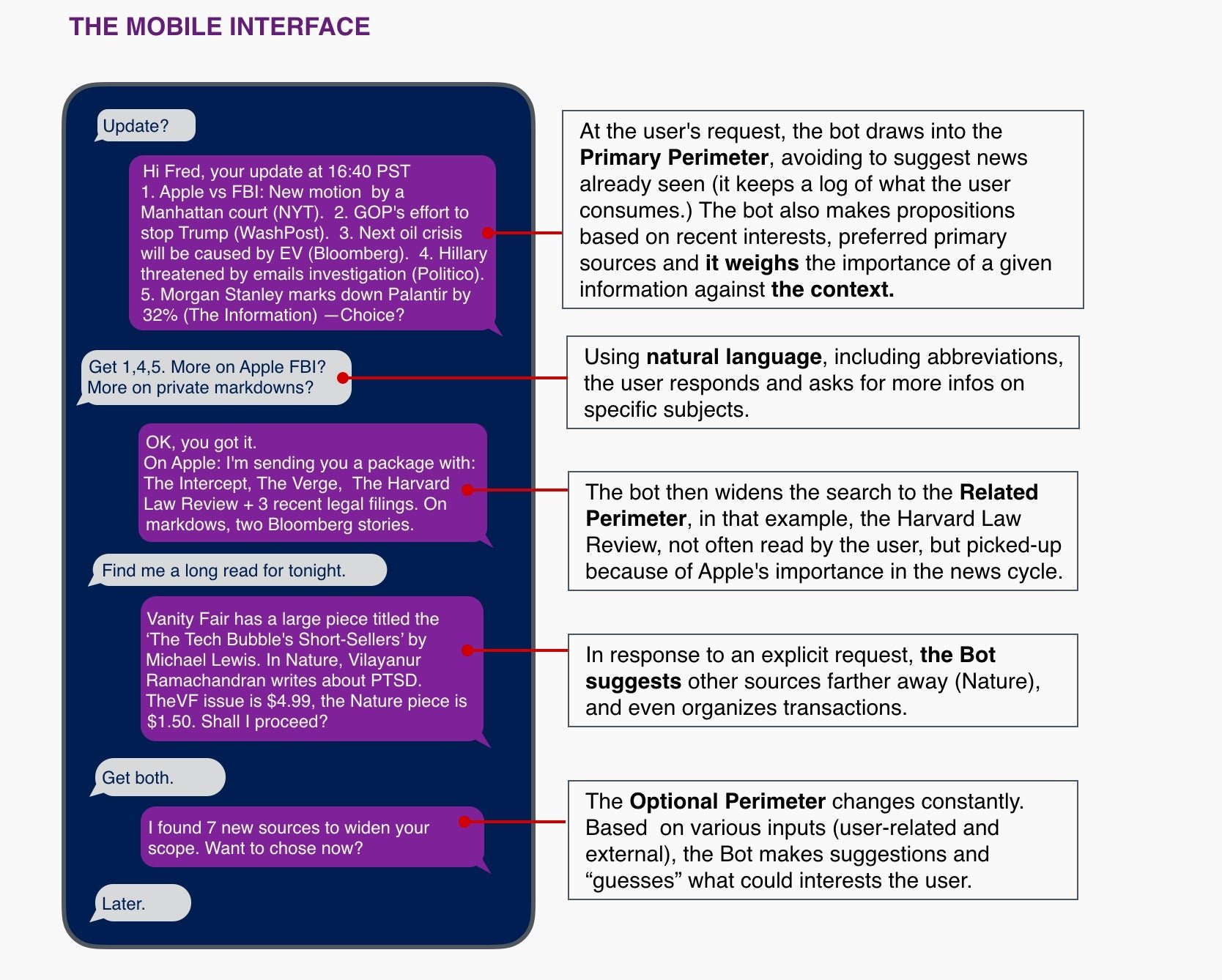
At this stage, three elements are essential:
One, this can only work on an explicit opt-in basis. Two, it can only involve a small portion of the data the aforementioned big players have accumulated about a user; if my political affiliation can be inferred from my readings, I might not want other inferred information, such as health or financial data, to be used in my NewsBot profile. Three—and that’s an obvious prerequisite—the Googles, Facebooks et al. should be willing to hand over their data to a third party (they actually should accept if I demand it, it’s my data, after all). Let’s be clear: It will be a while before that happens. For the most part, Google is petrified by the multiple privacy-related attacks it faces in Europe. Too bad for the news business.
Which brings us to a burning and more general question: Who should be the custodian of our profile data, whether inoffensive aspects like our reading habits, or the most critical elements such as health or financial data?
In Europe, most will suggest that the government should be the custodian of these data.
I beg to differ, especially within the political context: as I said in a news show last Friday, Feb. 26, on France Inter (the French public radio), democracies are great, but they are inherently unstable. Think of the minister of justice and the head of national intelligence that could be appointed by a Donald Trump or a Marine LePen. Plus, states are notoriously incompetent when it comes to technology; we can be sure that leaks will be abundant and the datasets poorly managed. Lastly, if a state owns individual data, it will be prone to invoke any national security consideration to use or abuse this data.
Others might think it’s better to leave our precious data to the private sector. First of all, they’ve had it for a long time. Before the era of Google and others, American companies like Equifax, Experian, or TransUnion knew everything about every citizen’s financial situation, while Axciom and others had the rest. But Google or Facebook are not immune to a conflict of interest as they collect tons of data for advertising purposes. As for Apple, my personal theory is that it let its advertising initiative fail precisely to avoid such conflict of interest, and to offer itself as the ultimate and most reliable custodian of the data it has about us—a timely position given Apple’s fight with the US department of justice.
Coming back to the news sector, it definitely needs to develop a more data-centric—or more specifically, an appetence-centric—approach for its customers. Today, in order to maximize ad revenue, the news sector subcontracts the job to others players. It should now consider what it needs to do to better acquire and retain loyal readers and viewers.
This post originally appeared at Monday Note.