Tomorrow (Aug. 5), an artificial intelligence system called the OpenAI Five is set to play against a team of five professional e-sports players in Dota 2, a game that requires fast-twitch reflexes, an encyclopedic knowledge of the game’s strategies, and most of all, teamwork.
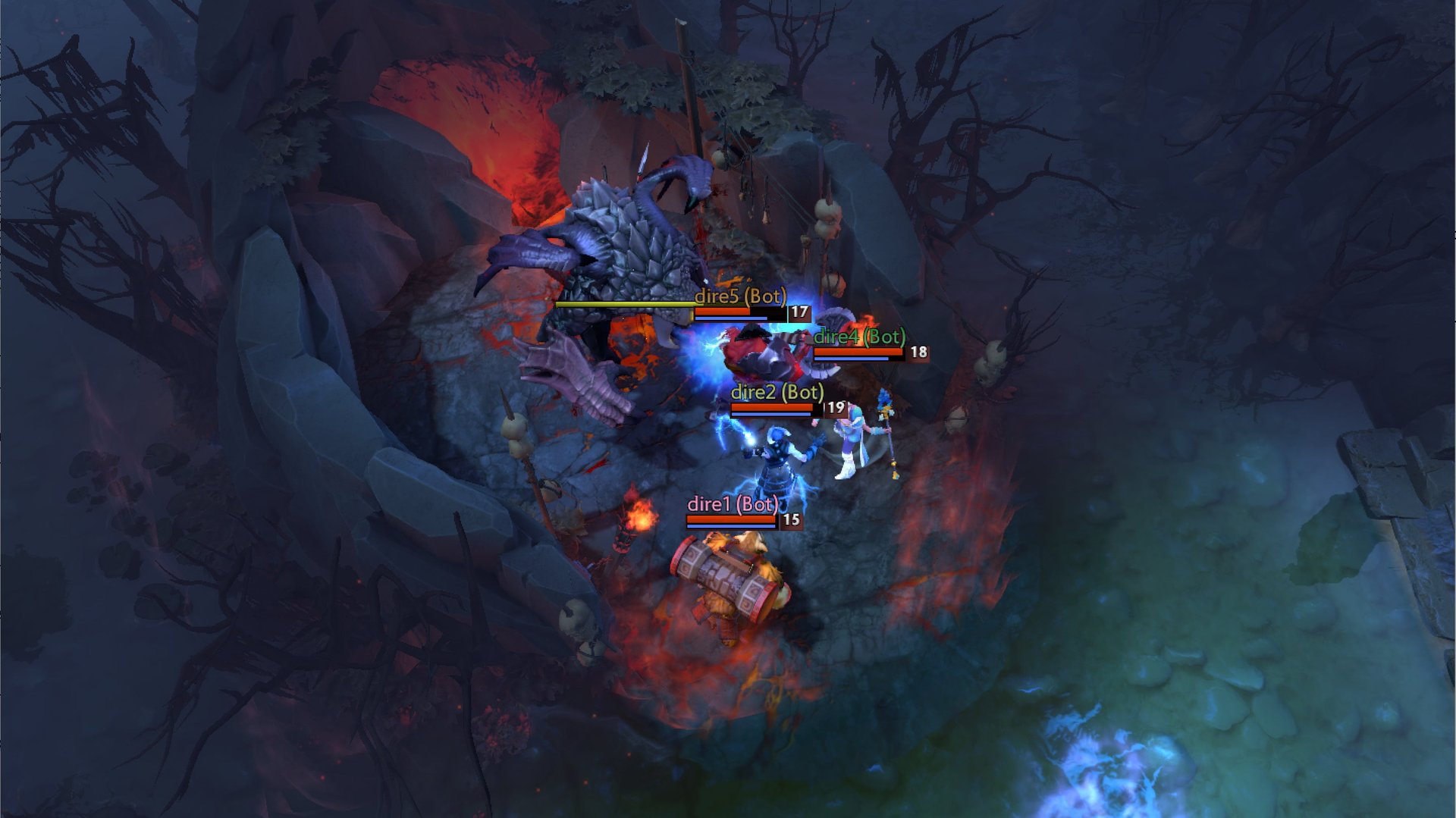
Tomorrow (Aug. 5), an artificial intelligence system called the OpenAI Five is set to play against a team of five professional e-sports players in Dota 2, a game that requires fast-twitch reflexes, an encyclopedic knowledge of the game’s strategies, and most of all, teamwork.
In the video game, two teams of five players are placed at opposite ends of a square arena, and fight past each other using melee and spells to destroy their opponent’s base. It’s one of the most lucrative e-sports right now, with this year’s biggest tournament garnering a prize pool of more than $23 million. For the researcher’s software to win against the pros, it would be like a robot learning to dunk on Michael Jordan.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
Games are an easy way for those of us without PhDs to understand how far AI research has come: When put in complex situations, can an AI beat humans? We understand what it meant for IBM $IBM’s DeepBlue to beat Garry Kasparov in chess, and DeepMind’s AlphaGo beating Lee Sedol in Go—decades of human practice and skill were defeated by mechanical computation. Outside of those publicized matches, AI researchers have worked for decades to build AI agents that are superhuman at playing Atari games, checkers, and even Super Smash Bros.
Not all of the research that’s done on video-game playing AI is applicable outside of the lab, but outside of the competition, OpenAI is showing that its brand of research can be broadly applicable. An example: The same algorithm that is set to play Dota 2 tomorrow can also be taught to move a mechanical hand.
One of the most popular methods for teaching bots to play games, the technique used by OpenAI, the AI research lab predominantly founded by Elon Musk and Sam Altman, is called reinforcement learning. It’s when you give a bot an objective, like collecting coins, and rewarding the bot when it completes the objective. At first, the bot’s movements are completely random, until it accidentally figures out how to complete the task. The moves the bot used to complete the task are weighted as better, and the bot is more likely to follow those actions when it tries the next time. After hundreds, thousands, or millions of attempts, strategies emerge.
OpenAI’s Dota 2-playing bot, for instance, plays millions of games against itself over the course of two weeks. Throughout each game, the bots’ reward is shifted from getting points for themselves to increasing the overall team’s score. The research team calls this “team spirit,” as Quartz previously reported.
Games are such a good place for AI to learn because they’re an analogue of the real world, but with an objective, New York University AI professor Julian Togelius told Quartz.
“The real world doesn’t have interesting tasks,” Togelius said with a laugh. “Games are perfect, they have rewards right there—whether you win or not, and what score you get.”
And games can be played an infinite number of times—they’re just software, and can be played at the same time by thousands of bots to multiply the speed at which they find the solution or strategy.
But a pitfall of this method is that what the bot learns to do is completely dependent on the reward. The algorithm has no conception of how a video game is supposed to work, so if there’s a bug or a glitch in the game, the bot will just do the easiest thing that gives it the reward.
Researchers at Germany’s University of Freiburg found this out when training a reinforcement learning algorithm to play the Atari game Q*bert earlier this year. Instead of learning to play the game like a human would, it learned to lure its enemies into killing themselves by jumping off the side of the stage, knowing that the enemy would follow. The game counted the enemy as killed and gave the bot an extra life and points, so it was a net gain.
The bot also found a glitch where if it jumped from platform to platform, it could break the game into giving it hundreds of thousands of points. Technically, it was doing its job: Getting points. But it wasn’t really learning to play the game.
Togelius’ work has recently focused on making better game-playing bots by randomizing the levels of the games that the bots play each time. Since the bot never plays the same level twice, Togelius says that the bot isn’t just learning to find a hack or figure out one strategy—they’re actually learning to complete a task in any scenario.
OpenAI’s video game pursuits aren’t just about beating pros in a game, but learning how to make thousands of small decisions that achieve a larger end goal. An example is another OpenAI project that’s using the same learning system and algorithm as the Dota 2 bots: its researchers have designed an algorithm to control mechanical hand that can hold a block and use its fingers to manipulate it into specific orientations.
These two projects were started at about the same time, Jonas Schneider, a member of the technical staff at OpenAI, told Quartz. But when the Dota 2 team showed off their progress beating human professionals at the game last year, Schneider says the robotics team realized the potential of the reinforcement learning system.
“We basically reached the same level of performance using the exact same code that was used for the Dota experiment,” Schneider said. “Within just a couple weeks we reached parity with what we had been trying to build for months before. I think we were all very surprised.”
These experiments are run using a program built by OpenAI called Rapid, which coordinates thousands of processors that run hundreds of reinforcement learning algorithms at the same time. Each algorithm powers a bot, which plays through the game or a simulation of moving the hand, and then syncs what it’s learned to the rest of the bots when the trial is over.
Using computing power that’s thousands of times greater than the average laptop computer, the mechanical hand has been able to achieve impressive dexterity without needing humans to code how each individual finger should move.
While OpenAI uses similar code to train both its game-playing AI and a robot, an important distinction is that they’re each learning how to complete their tasks separately. If you tried to make the Dota 2 bot control a hand, it wouldn’t be able to at all: The algorithms are general enough to learn multiple skills, but still only those skills.
“We haven’t seen a lot of things that are trained on a game and then transferred into the real world,” Togelius said. “But what we have seen are that the methods invented for playing a game transferred to the real world.”
And OpenAI’s Rapid reinforcement learning system isn’t the first technique to be developed from video games and translated into the real world. The Monte Carlo Tree Search (pdf), an algorithm that was originally developed to play the game of Go more than 10 years ago, is now used for tasks like planning and optimization, Togelius said. The European Space Agency used the same algorithm to plan interplanetary trajectories for space probes, and it was also the backbone of DeepMind’s AlphaGo algorithm, which beat world champion Lee Sedol in 2016.
For OpenAI’s robotics team, Dota 2 seems like a validation that this technique can be used for more complex work in the future. The Dota 2 system uses more than 20 times the amount of the computing power that the robotic hand does, and trained for two weeks instead of the robot’s hands two days—meaning there’s room for the robotics team to tackle problems that might take more time to learn.
“We’ve been surprised how far we can get with pretty much existing algorithms, so we hope to some extent that Dota will be kind of the last video game milestone,” Schneider said. “It’s clear that if a game as complex as this can be solved by reinforcement learning, that will be the ultimate test for reinforcement learning and video games.”