
With the heady perfume of big data permeating much of the intellectual atmosphere, the field of economics is increasingly tilting toward empirical efforts, according to a recent paper published by Stanford economics professors Liran Einav and Jonathan Levin in the journal Science. That means in order to move up the career ladder, economists are becoming more reliant on digging up novel data sets to work with.
The Stanford economists looked at papers published in the last few years in the American Economic Review, one of the world’s most prestigious economic journals. And they found that a growing share of those published were exempt from the journal’s data availability policy, which stipulates that data used in papers must be publicly available so that other economists can try to replicate the findings. Such exemptions are sometimes granted in the case of proprietary data. And that type of closely held data set has been at the heart of some of the most influential economic papers of the last few years.
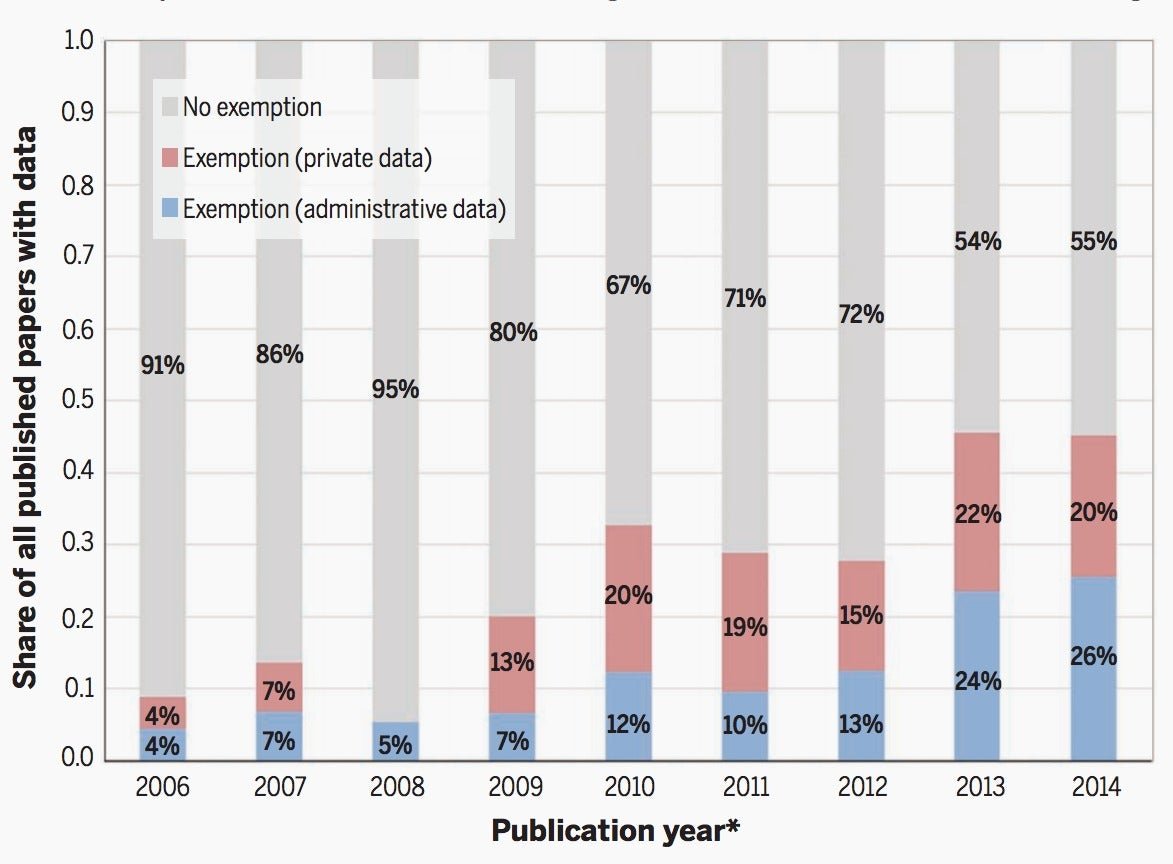
For instance, one paper used large samples of US tax records to identify the parts of the US where people are able to rise above their socioeconomic level at birth, and to see where there is less economic mobility. Another used data from the US health care programs Medicare and Medicaid, allowing economists to produce incredibly detailed maps of variations in diagnoses and treatment. A third used US tax records to follow up on students decades after they finish their education, to identify earnings boosts linked to early childhood education [pdf].
While these vast stashes of detailed administrative data are produced by public agencies—the government outfits that collect taxes and manage social welfare programs, for example—the databanks that were so crucial to the production of these high-impact papers aren’t available to just anybody. As journalists well know, a combination of privacy and confidentiality concerns, as well as bureaucratic foot-dragging, can make acquiring public agencies’ records a feat of near-superhuman persistence.
Similarly, giant firms such as eBay, Google $GOOGL, and Facebook $META are constantly amassing ever-richer hoards of data that can shed real light on economic conditions, sometimes down to the individual level. Some of this information is publicly available. For instance, one recent paper reported that the proliferation of job-related tweets—using phrases such as “lost my job”—could help discern labor market trends. Google’s own economists have argued search traffic has had provided a pretty good reflection of short-term fluctuations in US economic conditions.
But again, getting access to closely guarded data held by private companies requires significant investments of time and energy by economists. And the access to privately held data can come with ethical conflicts. What if an economist granted access to troll through a company’s data uncovers an economic finding that the company would prefer to keep private?
A fascinating recent paper noted that the reliance on hard-to-obtain data is one avenue by which economists (who desperately need those datasets for the publishing that is essential to their advancement) can become “captured”—much in the way financial regulators are often overly influenced by the industry they attempt to regulate, or journalists can become too cozy with sources. “Access to proprietary data provides a unique advantage in a highly competitive academic market,” wrote University of Chicago Business School professor Luigi Zingales. “To obtain those data, academic economists have to develop a reputation to treat their sources nicely.”
In other words, while exciting new stockpiles of data can generate a lot of important new insights, caution is warranted. Dr. Einav, one of the Stanford professors who wrote the paper for Science, says that academic journals are still trying to work out their standards for data availability from highly restricted sources.
But he knows from his own research that it isn’t always possible to share underlying data. For instance, he recently co-authored a pair of papers (here and here) on the impact of taxes on internet commerce using data he sourced through a partnership with the e-commerce giant eBay. But he couldn’t actually post eBay’s proprietary underlying data he used to come up with his findings.
“Like most things in the world, it’s a tradeoff,” Einav told Quartz. “But if the most exciting data sets are coming form these companies … an extreme view that we should never let anything get published unless things are kind of postable, [means] you’re going to lose a lot of the most exciting stuff in the world.”