In 1905, Albert Einstein derived that light was composed of particles by fitting his theory to just a handful of data points. This discovery changed our understanding of basic physics and helped usher in a new era of quantum mechanics. Today, scientists often need to interpret much larger data sets to drive discoveries.

In 1905, Albert Einstein derived that light was composed of particles by fitting his theory to just a handful of data points. This discovery changed our understanding of basic physics and helped usher in a new era of quantum mechanics. Today, scientists often need to interpret much larger data sets to drive discoveries.
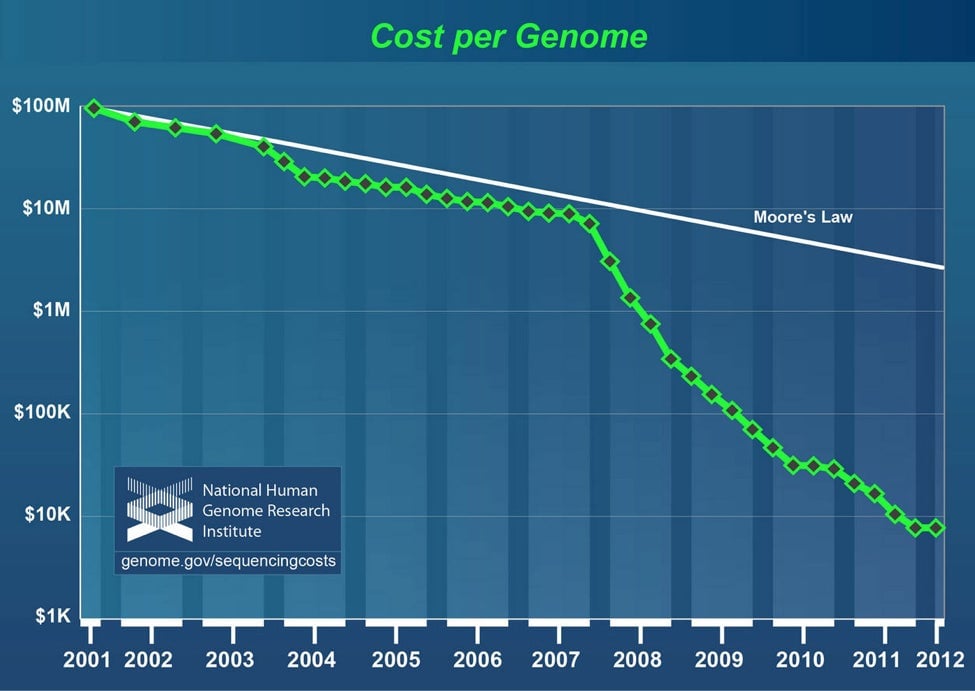
A little more than a decade ago, the first sequencing of a human genome cost $100 million. Now, the same results cost no more than a used car. At about 0.8 to 1 terabyte, the full genome creates more than 4 million times the amount of data that Einstein was investigating. Some scientists and researchers are using tools that were developed by online commerce and search engines to tackle these new questions.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
In 2003 and 2004, Google $GOOGL published two papers that explained how the company repeatedly digests almost the entire internet to collect data for our searches every couple days and, eventually, hours. (Google recently moved away from this system of indexing onto something new that could log the Web in real-time and scale up to millions of machines.) The findings shook the industry. Often, to process tons of information, companies bought very expensive, very reliable, very fast computers that churned data as quickly as the newest technology could. Budgets being budgets, only a few of these premium boxes were in place at any one time. Instead, Google segmented the work into small pieces that were distributed onto thousands of cheaper computers that could produce the type of intelligence that we are now accustomed to in searches. If the old way was a single farm to grow flowers and collect pollen, then this new system was thousands of pollen-hoarding bees that distributed themselves to fields far and wide. The less expensive hardware now being employed to crunch data meant more computers were afforded in a budget while maintaining reliability. If a few computers went down, there were thousands left to pick up their duties.
Some scientists, often working on shoestring funding, thought they could greatly benefit from this approach. Before that could happen though, the vague description in Google’s papers had to be developed into a more concrete system. Yahoo, and others, helped do just that by developing a free version of Google’s methods called Hadoop.
Making sense of large distributed data through splitting up the processing and coalescing of small data chunks is exactly what Hadoop was designed to do. Soon, scientists were powering software with Hadoop to accomplish exactly the tasks needed for genome research. Another innovation was needed though. Hadoop was built to work on a large number of cheap computers, but scientists don’t have thousands of computers like Google and Yahoo. The solution came from the ability to obtain these resources using Infrastructure as a Service cloud computing.
Cloud computing is based on a pricing model that rents, sometimes large, computer resources for a very short period of time—think home supercomputer for an hour. Jason Stowe, CEO of Cycle Computing, recently challenged scientists with the question: “What impossible problems are solvable given enough compute power?” Victor Ruotti, of the University of Wisconsin at Madison, wanted to analyze gene expression of stem cells and create a database that would allow scientist to identify the many different cells that one would find in an experiment. Like a giant phone book of cells, he wanted to make it easier to look up the information. Using over a million processing hours, he was able to finish his study in a week and it cost less than $20,000 using Amazon $AMZN’s cloud. Large scale temporary technology deployments are now being used by financial companies to analyze portfolios quicker, the New York Times to make its archives accessible using Hadoop, insurance companies to determine an annuity’s health, and drug companies to help develop new cures.
When Einstein made the discovering in the story above, he did so with a small data set. Decades later another physicist, Erwin Schrödinger, derived an equation that explained most of the budding ideas in quantum mechanics. The data processing needed to solve it, however, was prohibitive. Physics immediately derived estimates for solutions and was one of the earliest adopters of computers partly for this reason. It is not that small data problems are no longer important, it is that even solutions lead to new questions, and science doesn’t want to be bound by computational difficulty in the pursuit of answers.
In computer science there are two laws, Amdahl’s and Gustafson’s. Amdahl’s shows how much faster a given problem is answered when more processing power is thrown at it. Gustafon’s turns Amdahl’s on its head by defining how big of a problem can be answered, given a fixed amount of time, when more resources are available. In other words, given an hour, what can be solved with more computers vs. with less. Science, like Gustafson suggested, often opts for bigger questions vs. saved time. The ability to translate larger amounts of data into cogent explanations can help remove old barriers from scientific pursuits. In genetic research, that could mean unlocking the causes of diseases, developing new cures, and finding the parts of the genetic blueprint that make us human.