A simple look at the components of an HTML page tells a lot about the reliability of its contents. Problem is, distribution platforms don’t bother looking at those signals. (Part of a series about my News Quality Scoring Project.)

A simple look at the components of an HTML page tells a lot about the reliability of its contents. Problem is, distribution platforms don’t bother looking at those signals. (Part of a series about my News Quality Scoring Project.)
As a microbiologist once said, the devil is not in the details, but in the structure. She was referring to the genetic arrangement of a deadly strain of virus. The digital world bears some resemblances to a living organism. It morphs constantly, it is unstable, and there is much organic garbage strewn around. For example, on The Guardian, for a single character of article, you can expect about 100 characters of code; more on that here.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.
Journalism’s visual tradition dictates providing a minimum set of elements to let readers assess the origin of information. For instance, a story must display from where it is reported or written, and by whom. We are supposed to know a little about the authors, sometimes with access to heir and body of work. The Trust Project at the University of Santa Clara focuses on developing standards for better journalistic transparency (see its list of indicators). My own project at Stanford’s John S. Knight Fellowship is complementary to the Trust Project.
The News Quality Scoring Project (NQS) is aimed at finding and quantifying “signals” that convey content quality. The idea is to build a process that is scalable and largely automated. Incidentally, it will contribute to debunk fake news by “triangulating” questionable sources—see this previous Monday Note.
As of today, we just completed a collection of 640,000 articles resulting from three weeks of gathering data from 500 of the largest American websites and their 850 corresponding RSS Feeds. The task is now extracting and analyzing relevant signals, assessing their relevancy, reliability, and resistance to tampering (more on this in a few weeks).
Coming back to the HTML structure approach, let’s look at the components of a basic article on the web:

This is (or should be) the basic structure of an article page in a news website. The implicit setup is not without importance. Let’s go into details:
In theory, it is the most verifiable indicator of quality. But the magic of the web tends to blur it. First, producers of false information have deployed great skills at mimicking legitimate information outlets. For more on this, read this Medium post by Aviv Ovadia, creator of Media Window that “tracks the credibility of online news media.”
The simplest way to address source legitimacy is to send a query to a domain name registry (Whois) to determine how recent the domain registration is, if it has been done anonymously, etc. This is done easily and automatically. Such a simple process applied to this list of alt-right sites compiled by Indiana University would have prevented a burst of fake news.
The second issue with source qualification is tied to the rise of distribution platforms (Facebook $META, Google $GOOGL, Apple $AAPL News…). The Tow Center for Digital Journalism at Columbia University recently published an in-depth report titled “The Platform Press: How Silicon Valley reengineered journalism“ that reminds us of some worrying stats (emphasis mine):
Pew [Research] found that only 56% of online news consumers who had clicked on a link could recall the news source (2016). And the American Press Institute’s Media Insight Project (2017) found that on Facebook only two of 10 people could recall the source, while far more trust was placed in the sharer. “If we’re out here for branding and nobody even recognizes it, if our brand is related to the Snapchat brand then . . . maybe it’s not worth it,” says one magazine publisher.
The Tow report—a must-read—is a mild call to publishers to reconsider their relationship to distributions platforms. (Many of its arguments are sweet music to my ears. I always defended here the idea of using platforms as promotion and recruiting tools, especially towards non-core—but important—audiences such as young readers who will become subscribers. That said, because audiences remains controlled by platforms while media brands evaporate, I also argued against using platforms for publication purposes.)
A simple way to test its reliability is to evaluate its clickbait level and/or to confront the subject of the story to the rest of the news cycle. Unless the media is The Intercept or another one known for its exclusives, the likelihood that a unknown outlet will scoop everyone else is limited. Therefore if a “fact” doesn’t have resonance on the web, it’s probably bogus.
I already addressed this question in the last Monday Note. Like for sources, it now seems indispensable to build a whitelist of news authors, in the broadest sense of the word. This database needs to include not only reporters and editorial staff, but also freelancers, selected bloggers, experts, and op-ed writers. Building it is not an easy task (I know it first-hand); among other hurdles, it is potentially a red-hot issue among journalists, and deciding on the criteria for whitelisting is tricky. But: a) it is quite likely that the largest distribution platforms already have or will create such a database, and b) making such data widely accessible is a must if we are to prevent the proliferation of misinformation.
It’s a question of coherence: if a long story is accompanied by some unattributed photograph (therefore possibly stolen), or a stock photo bought for a few bucks (and easily identifiable), something is fishy. The same goes for video. There has to be some consistency between the editorial effort for text and for iconography.
In the list of signals I established for the News Quality Scoring Project, the analysis for photo or video goes like this:
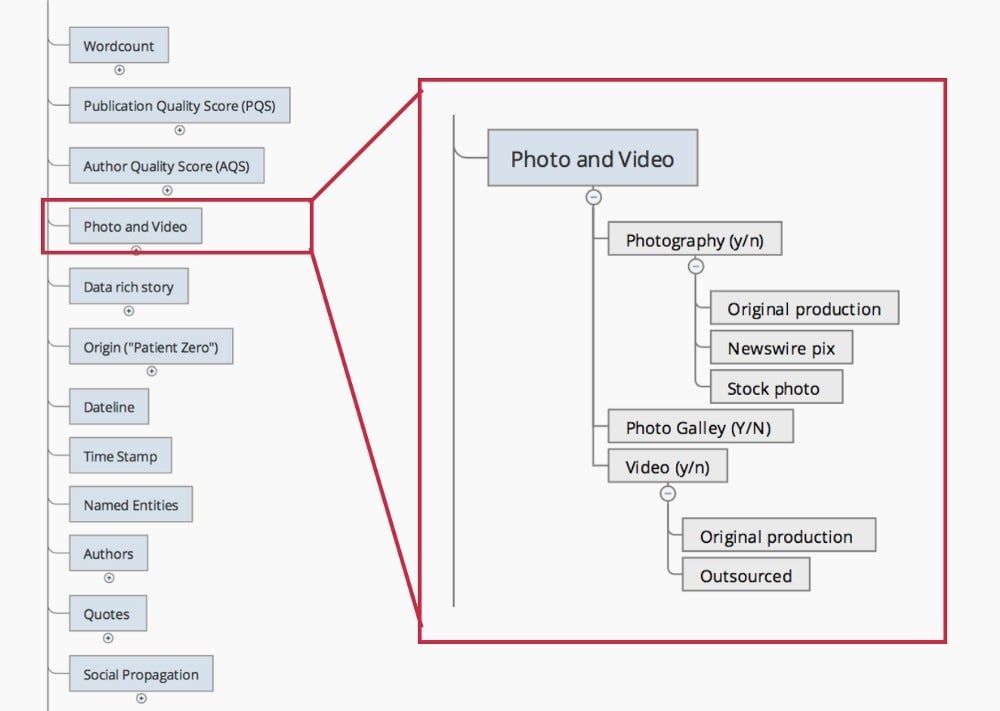
The final score is a combination of sub-signals—the trickiest being finding the right weight between major and minors signals, or between the most reliable and tamper-proof vs. the easily faked ones, etc.
Assessing the body text is a topic in itself. Scores of technologies and services are able to perform good semantic analysis, ranging from the structure or richness to tonal analysis. A good journalistic story has some characteristics in terms of density that can be automatically assessed, such as the proportion of quotes, named entities, etc. But these can easily be made up. (More on this later in a dedicated Monday Note.)
Legitimate news outlets tend to produce a lot on the same subject. Inventory depth is reflected in “Related stories” boxes or sidebars. In short, an article with no additional reading recommendation from the publisher should raise suspicion. This can be easily spotted by looking at the linking structure of the HTML page, or at the presence of a recommendation engine.
That’s the easy part: most legit media often provide all the information about themselves or their parent company with ways to contact them at the bottom of the page—or a link giving access to the relevant part.
A problem with this deliberately sketchy outline is it only applies to the content that is put on the publisher’s website. Distribution platforms tend to relieve publishers of their obligation to abide by the design conventions stated above which, to some degree, warrant reliability. Maybe this is a step platforms should consider: forcing sources they host to display (and verify) basic signals of legitimacy.