The reason why most of the images that show up when you search for “doctor” are white men
Every day, machine learning algorithms underpinning Google and Facebook decide which information we see and who we interact with. It might seem that artificial intelligence’s decisions would be made without the socially constructed prejudices of humans, but algorithms, too, can be biased towards or against certain genders, ethnicities, or social groups—though that’s likely our fault.
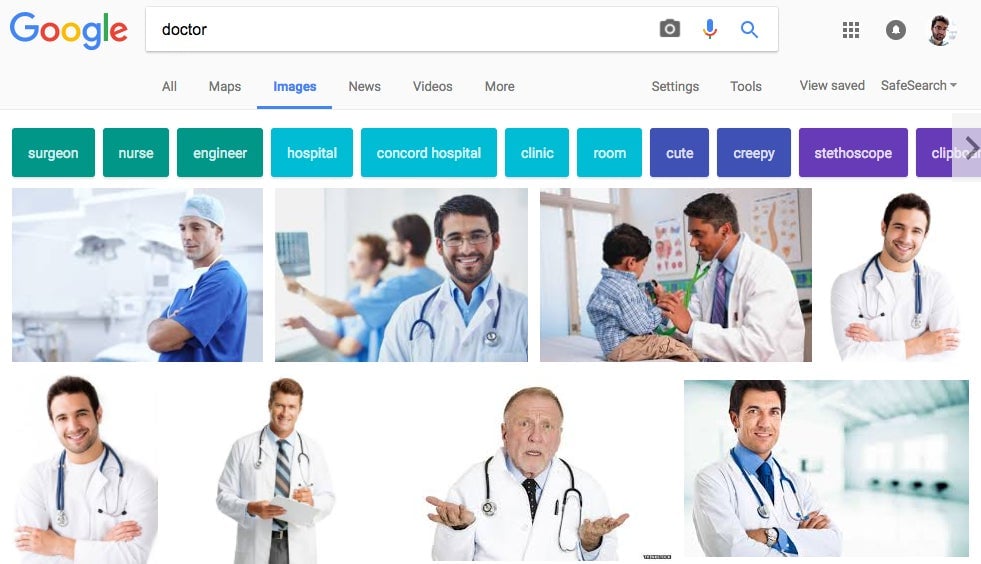
Every day, machine learning algorithms underpinning Google $GOOGL and Facebook $META decide which information we see and who we interact with. It might seem that artificial intelligence’s decisions would be made without the socially constructed prejudices of humans, but algorithms, too, can be biased towards or against certain genders, ethnicities, or social groups—though that’s likely our fault.
Research from Princeton University suggests that these biases, like associating men with doctors and women with nurses, come from the language taught to the algorithm. As some data scientists say, “garbage in, garbage out”: Without good data, the algorithm isn’t going to make good decisions.
The essential business news, delivered fresh every morning.
Join 500,000+ readers who start their day with Quartz.
By subscribing, you agree to our Terms of Service and Privacy Policy.