
Imagine handing over a complex set of construction plans to your building contractor, fresh off your fancy $12,000 Xerox WorkCentre scanner/copier/printer (link in German), only to find there were errors in the blueprints that weren’t on the original. Or, imagine passing a set of budget figures to the CFO of your company that weren’t the ones you fed into your WorkCentre, one of Xerox’s midrange color multifunction machines that, like any scanner or photocopier, is expected to reproduce a picture of the document you put in. As anyone who uses one of these devices in an office, school or home knows, whether photographing or digitally scanning a document, the camera doesn’t lie. Or does it?
That’s why German computer researcher David Kriesel was so confused when he removed scanned construction plans from his WorkCentre recently (link in German) and found the reproduction did not match the original he had put in, but in a strange way: perfectly legible digits on the original had turned into different ones in the copy made by his WorkCentre. Not just fuzzy numbers that could be a 5 or a 6, but a wholesale substitution of one number for another. Somewhere in the machine, the document seemed to enter a parallel universe and produced a non-copy of the original. His machine wasn’t using optical character recognition (OCR) to read the document—it was supposed to be just taking a straight picture, and reproducing the plans.
According to Kriesel’s blogged account, intrigued, he then ran a set of cost figures from another document through the scanner and found a similar appearance of new figures in place of old ones. After testing additional documents and finding more new numbers, Kriesel theorized—correctly, as it turns out (link in German)—that the culprit in this digit swapping is an image compression technique the WorkCentres use, called JBIG2, which creates its own library of image patches to make up for unclear data. Essentially like an autocorrect with pictures instead of words, JBIG2 looks for a best-effort match within a particular range of error for images it can’t fully process, in this case, using other numbers from different parts of the document.
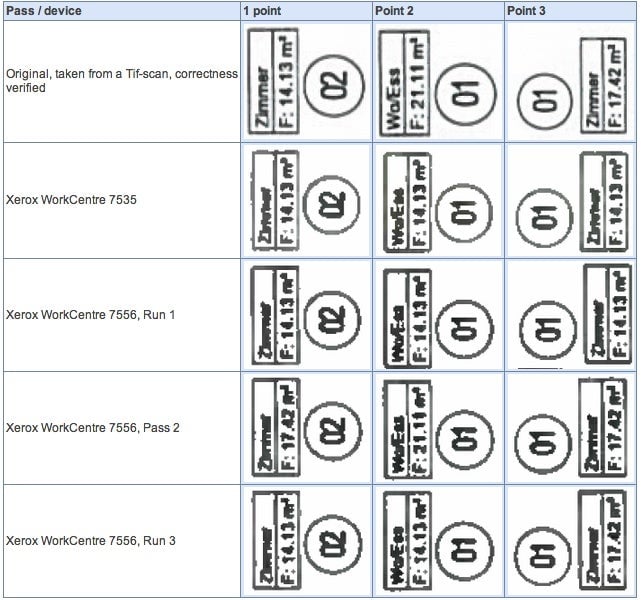
The result is that the compression algorithm can swap incorrect number images into a document to fill in blanks where it doesn’t have good data. One typography blog has put part of the problem down to the simple misapplication of fonts that are too similar, easily fooling the algorithm. Kriesel blogged that he has spoken to Xerox and the company is apparently looking at a patch to fix the issue, but the question remains, how many and what kind of errors have crept into other documents on other machines that also use this compression process?
It’s a harmless enough technical explanation, but even the occasional transposition of numbers can have potentially dangerous impacts when they involve critical data. Computers, like many machines, are always vulnerable to the GIGO rule (garbage in, garbage out), which says that the quality of a computing output is reliant on the quality of the input. But our increasing reliance on them to work at high speed with larger and larger datasets can lead to an amplification of the inbound or inherited “garbage”—in most cases seemingly harmless shortcuts in programming or assumptions about “acceptable” margins of error in data that, at speed, have the potential to produce large-scale errors.
One such example was uncovered recently by researchers led by Song-You Hong of Yonsei University in Seoul and others from South Korea and Colorado, who looked at how the outputs of supercomputers used in weather forecasting are impacted by the software they use. The paper, recently submitted to the American Meteorological Society, tested what is called the Global/Regional Integrated Model (GRIM), a software program currently being developed and refined for complex weather forecasting, on 10 different supercomputer platforms with 10 different processors.
The outcomes of the forecasts from the same software and data were found by the researchers to have slight variations, based on how these processors handle rounding errors when calculating long numbers to drive the forecasts. In other words, tiny differences in how each processor is designed to handle complex math result in variation in forecasts using the same data. At the scale of a global weather analysis stretching over days, variations can lead to critically different outcomes that drive decisions from agriculture to tourism to logistics and transportation.
Other miscalculations can have a financial impact of a different kind. For example, one of the central characteristics of the anonymous digital currency bitcoin is that only 21 million bitcoins will ever be “mined,” or produced, as a means of controlling the supply. Based on the time it is assumed to take to mine each coin, which entails having a computing processor do a specific calculation, experts initially believed the full set of 21 million coins would be exhausted by 2140. However, as a result of unanticipated increases in the speed of processors being thrown at bitcoin mining—itself a product of the currency’s growing profile—some researchers now think that all bitcoins could be mined as early as 55 years sooner, based on an incremental acceleration of the mining.
None of these examples represents a previously unknown fault or flaw, but all illustrate the level of error that can creep into an increasingly computational culture. These “known unknowns” create openings for problems that can scale more quickly, or go unnoticed buried more deeply in code, or open the door to the manufacture of controversy where there was none, as is apparently the case with climate change skeptics and the meteorological paper.