
Algorithms are unseen forces that dictate much of our life on the internet: Google $GOOGL search results,what we see on Facebook $META, and even spam filtering in email. And these algorithms are getting smarter thanks to improving artificial intelligence. To do so, they need to learn from more and more information. More often than not, the data these machines learn from comes from humans; Google’s algorithms, for example, learn to recognize speech by listening to tons of Google voice searches performed by humans. AI researchers need to be careful that these data accurately reflect the real word—because, like humans, algorithms can learn to be biased based on what information they get. Spare5, an AI training data service, recently learned this lesson in probably the most adorable way possible.
Spare5 makes training data to teach AI about different things in the real world, like annotating thousands of pictures of food so your phone’s camera eventually can recognize pizza on its own. According to a blog post on TechCrunch, they decided to run an “adorable little brain break” for their workers: Rating pictures of puppies, on a scale of 1 to 5 stars.
But when they got the data back, they were surprised by the results. Women gave higher cuteness ratings than men. On average, women rated each dog 0.16 stars more cute.
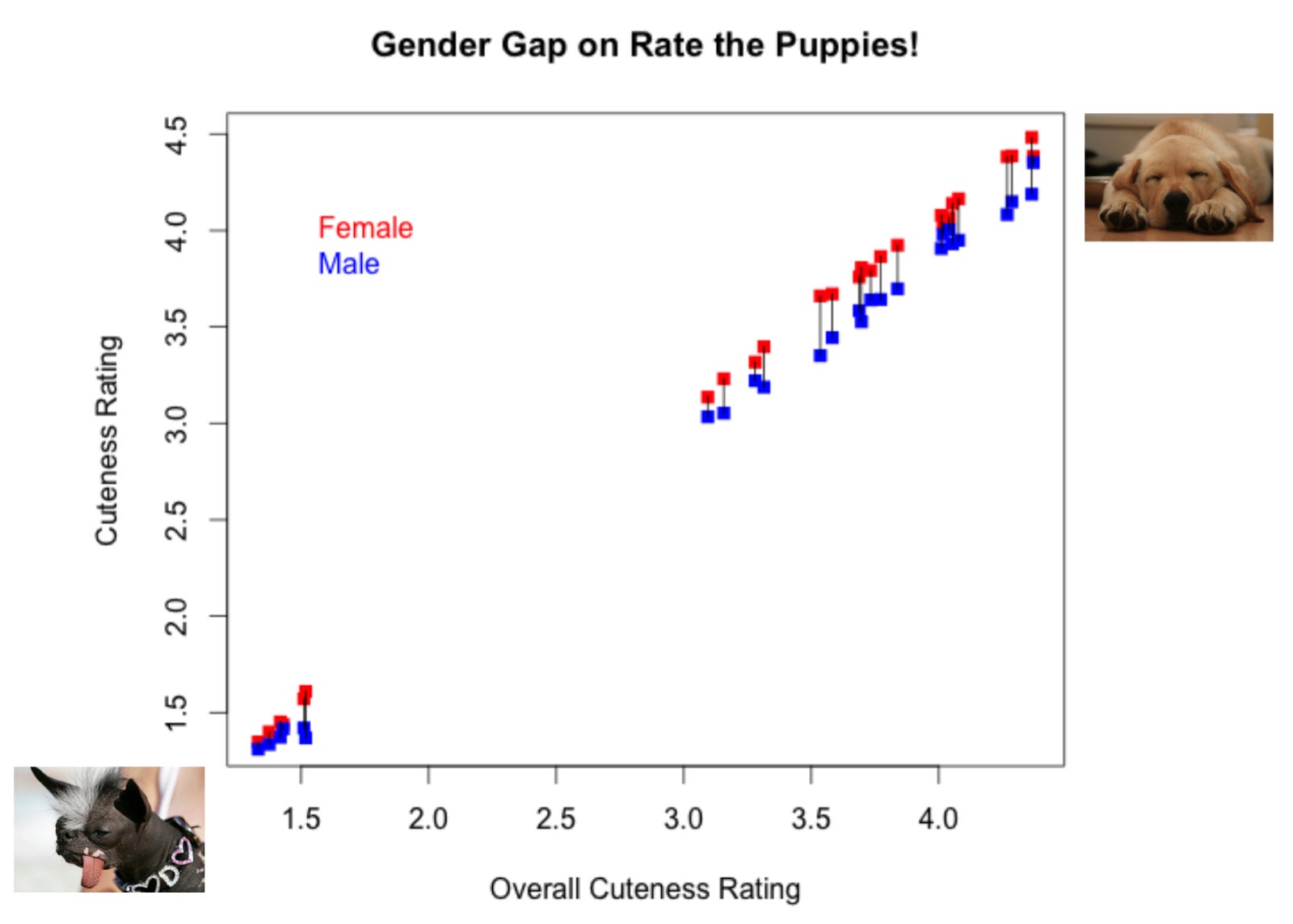
“This was a simple example: binary gender differences explaining one subjective numeric measure of an image. Yet it was unexpected and significant,” the company’s CEO, Matt Bencke, wrote.
So how would this affect an AI? Say a researcher was building an app where you could upload a photo of your dog, and the app would rate it and rank it among other pets out there. If the researcher’s training data only sampled men, the algorithm would be a harsher rater.
Given enough data, other biases might emerge. If men preferred small dogs and women preferred large dogs, and the researchers used more data from men, then the algorithm would lean towards ranking smaller dogs cuter, because those dogs are better-known by the algorithm.
When the stakes aren’t that high (it’s pretty tough to hurt a puppy’s feelings), this just seems like a fun example of the small preferential differences between different demographics. But it can also serve a reminder for those choosing data that their decisions carry the potential for greater consequences. In 2015, Google Photos categorized two black people as gorillas, as a result of a biased algorithm. The researchers behind the project later admitted that people with dark-skinned faces weren’t being categorized correctly.
As a simple corrective rule, Bencke suggests that data scientists look for diversity in three places: themselves, their data, and those generating the data.
We’re not in a place where every algorithm is perfect—and it doesn’t seem like we will be for a long time—but at least we get to learn something from puppies along the way.